15+ Years
Enterprise software delivery since 2009 — a track record built across technology cycles, not just the current AI wave.


Most of what your business knows is locked in text nobody has time to read — tickets, contracts, emails, reviews. We build NLP that turns it into structured, reliable data at production volume: classification, entity extraction, sentiment, and summarization, with accuracy you can measure and a cost-per-item that survives millions of documents. Classical models, fine-tuned transformers, or LLMs — we pick whatever hits your numbers, not whatever's in fashion.


A decade of AI engineering experience, validated in numbers
Search by meaning, not just keywords — embeddings and hybrid retrieval that find the right text even when the wording differs. The NLP foundation behind modern search and RAG.

When a task genuinely needs an LLM's flexibility — complex extraction, nuanced summarization — production LLM applications engineered with evaluation and guardrails, not a thin wrapper.
Generation on top of understanding — drafting, rewriting, and content built on the same NLP pipeline that reads and structures your text.

Wire NLP into the systems where your text lives and your output is needed — CRMs, ticketing, document stores, and data warehouses — so results flow to where work happens.
The conversational layer NLP powers — intent understanding and entity extraction behind a governed, auditable, production chatbot.

Turn the structured data NLP extracts into answers people can query in plain English over your warehouse — text becomes numbers, numbers become decisions.

When understanding text should trigger action — routing, responding, updating systems — agents that act on what NLP reads, not just report it.

Not sure which text tasks are worth automating, or whether your data's ready? Strategy and a costed roadmap that sequences the work before you build.

Automatically sort and tag text at scale — tickets, emails, documents, reviews — into your categories, with the accuracy and throughput a high-volume pipeline needs.

Identify and pull the entities and fields that matter to you — names, amounts, dates, clauses, custom domain terms — from unstructured documents, validated against your schema.

Understand how people feel and what they want — from reviews, tickets, and conversations — with sentiment, emotion, and intent classification tuned to your domain's language.
Our NLP systems are tailored to the specific text, terminology, and accuracy requirements of each industry.
Consulting & Advisory Extract and classify insight from the proposals, contracts, and reports consulting firms generate at volume.
Trusted by Rodic Consultants
SaaS & Digital Platforms. Build NLP features into your product — ticket routing, review analysis, and content tagging — at the scale your users generate.
Engineering & Infrastructure. Extract structured data from specs, reports, and standards, and classify technical documents at scale.
Financial Services. Extract entities and classify documents for KYC, compliance, and risk — accurately, auditably, and at volume.
Supply Chain & Logistics. Parse and classify orders, invoices, and supplier communications across high document volumes.
Healthcare & Research. HIPAA-aware NLP for clinical document extraction, research literature mining, and medical text classification.
CleanTech & Mobility. Classify and extract from reports, logs, and customer feedback across energy and mobility operations.
EdTech Platforms. Automate content tagging, essay analysis, and learner-feedback classification across your platform.
Non-Profits & Foundations Classify and extract from grant documents, surveys, and beneficiary feedback to stretch small teams.








We combine deep NLP and machine-learning expertise with enterprise delivery practices to ship text systems that are accurate, fast, and affordable at scale.
Enterprise software delivery since 2009 — a track record built across technology cycles, not just the current AI wave.
Independently certified, annually audited — meets the security baseline enterprise procurement actually checks.

Nine in ten enterprise clients return for follow-on work — the only measure of delivery quality that cannot be faked.

Verified client reviews, independently collected — real feedback from real enterprise engagements.

Certified cloud partnerships with AWS and Microsoft Azure — enterprise infrastructure standards from day one.

DataSense, DocSense, BidSense — proprietary pre-built AI products that go live in weeks, not months of custom build.

IP, data, and strategy protected before the first discovery call ends — not after contracts are signed.

Post-deployment optimisation included in every engagement — we stay accountable until the system is performing.

LLMs made everyone think NLP was solved — until the production bill arrives. For the high-volume, repeatable text tasks enterprises actually run, the cheapest, fastest, most accurate answer is often a smaller purpose-built model. Here are the truths that separate NLP that survives production from a prototype that quietly becomes unaffordable.
The trap in modern NLP is how cheap it is to start. A model call per document works beautifully in a prototype on a few hundred items — then production volume arrives and the same approach is suddenly ruinous. The economics, not the accuracy, are what kill most NLP projects.

NLP in production isn't a one-off question — it's the same operation running millions of times: every ticket classified, every contract parsed, every review scored. At that volume a fraction of a cent and a few hundred milliseconds per item become a budget line and a latency problem. A cost that's invisible in a demo is the whole conversation at scale.
We're called in again and again to rescue pipelines that proved out on a sample and then couldn't be afforded in production. The pilot validated that the task is doable; it said nothing about whether it's doable economically at your volume. Those are two different questions, and the second is the one that decides whether the project ships.
We model cost-per-item and latency at your real volume before writing the pipeline, so the approach we pick is one you can actually run continuously — not one that looks great in week one and gets switched off in month three. NLP is an engineering discipline with a budget, not a single API call and a hope.
The most important decision in an NLP project is usually made by default: should this task use a large language model, or something smaller and purpose-built? We pick on evidence — your accuracy bar, volume, latency, and budget — not on what's fashionable.

LLMs shine on varied, open-ended, low-to-moderate-volume tasks — complex extraction, nuanced summarization, work where you can't easily gather labels. When the task is genuinely hard and the volume is manageable, their flexibility is worth the per-call cost. We reach for them deliberately, not reflexively.
For high-volume, well-defined tasks — classification, NER, routing on millions of items — a fine-tuned transformer or even a classical model is typically faster, cheaper, more consistent, and easy to run on your own infrastructure. At scale that difference isn't a detail; it's the entire business case for doing the project at all.
The best systems combine both: an LLM to bootstrap labels and handle the rare hard cases, a small fine-tuned model carrying the high-volume production load. You get the LLM's capability where it matters and the small model's economics where it counts — instead of overpaying for one or under-serving with the other.
We benchmark candidate approaches on your actual data for accuracy, latency, and cost-per-item, then recommend the one that hits your targets most cheaply. We're not attached to LLMs or to classical NLP — only to what meets your numbers in production. Ask any vendor: 'When would you NOT use an LLM here, and why?'
Anyone can show NLP working on a handful of clean examples. The question that matters is how it does on the messy, real, edge-case-laden text you actually process — and you only know that if accuracy is a measured number, not a vibe from a demo.

We measure precision, recall, and F1 on a real labelled sample of your text — including the awkward cases — so "it's accurate" becomes a figure you can interrogate. A vendor who can't quote accuracy on your data can't honestly promise it, and can't improve it either, because they have no baseline to move.
99% accuracy on routing low-stakes tickets is overkill; 99% on extracting contract terms may be the minimum. We define the accuracy the task actually needs upfront, against the cost you can spend per item, so the solution is neither over-engineered nor quietly under-performing where it counts.
Because there's a measured baseline, every improvement is attributable — more labels, a model change, a rule — and visible on a dashboard. NLP accuracy isn't fixed at launch; it's a number you move deliberately, and we build the evaluation loop that lets you keep moving it.
Measurement also tells you where the model is weak, so we can flag low-confidence outputs for human review instead of letting silent errors through. Knowing the failure modes is what makes an NLP system safe to put in front of a real business process.
The bulk of what an organisation knows sits in tickets, emails, contracts, reviews, and documents — and most of it is never analysed because there's simply too much to read. NLP is how you turn that unread backlog into structured data you can actually act on.

Text piles up faster than any team can keep up with, so it stays buried and unused — the answers are in there, but nobody has time to find them. NLP processes it continuously, turning a days-long queue into near-real-time structured output without adding a single person to the queue.
People reading and classifying documents, or keying fields from forms, is slow, expensive, and inconsistent — and it only gets worse as volume grows. NLP automates the repetitive reading-and-sorting so your team handles the exceptions, not the volume, with the same rules applied to every single item.
Your customers tell you exactly what they think in reviews, tickets, and surveys — but at volume nobody can read it all. Sentiment and intent analysis turns that stream into trends you can act on instead of anecdotes someone happened to notice; one recurring complaint surfaced across thousands of tickets can be the root cause quietly driving churn.
A gap isn't a reason to wait. Start with one well-defined task on text you already have, with a clear accuracy target — classification or extraction on a single document type. That first working model proves the value and produces the labels and learnings that make the next task faster and cheaper.
Teams obsess over which model to use, but the thing that actually blocks most supervised NLP is a shortage of labelled examples. The model is rarely the hard part; getting enough good labels, affordably, usually is — and there are smart ways around it.

Supervised NLP needs examples labelled the way you want them classified or extracted, and most organisations have very few. Waiting for a perfect, fully-labelled dataset is how projects stall for months — so the real skill is designing the cheapest path to "enough labels to start", not chasing an ideal that never arrives.
One of the best uses of an LLM in an NLP project isn't production inference at all — it's generating a first pass of labels that humans then correct, which is far faster than labelling from scratch. You get a usable training set quickly, then run the high-volume workload on a cheap fine-tuned model trained on it.
Rather than labelling at random, we focus human effort on the examples the model is most unsure about — the ones that teach it the most per label. That targets a limited labelling budget at maximum accuracy gain, so you reach your target with far fewer labels than a brute-force approach would need.
Every labelled example and every correction you make is reusable — it improves this model and seeds the next task. A well-run first project doesn't just ship one model; it leaves you with a labelled dataset and an evaluation set that make everything after it faster, cheaper, and more accurate.
Every NLP system makes mistakes; the question is whether yours is a black box you can only shrug at, or a system whose errors you can see, understand, and correct. That difference decides whether accuracy improves after launch or stays stuck.
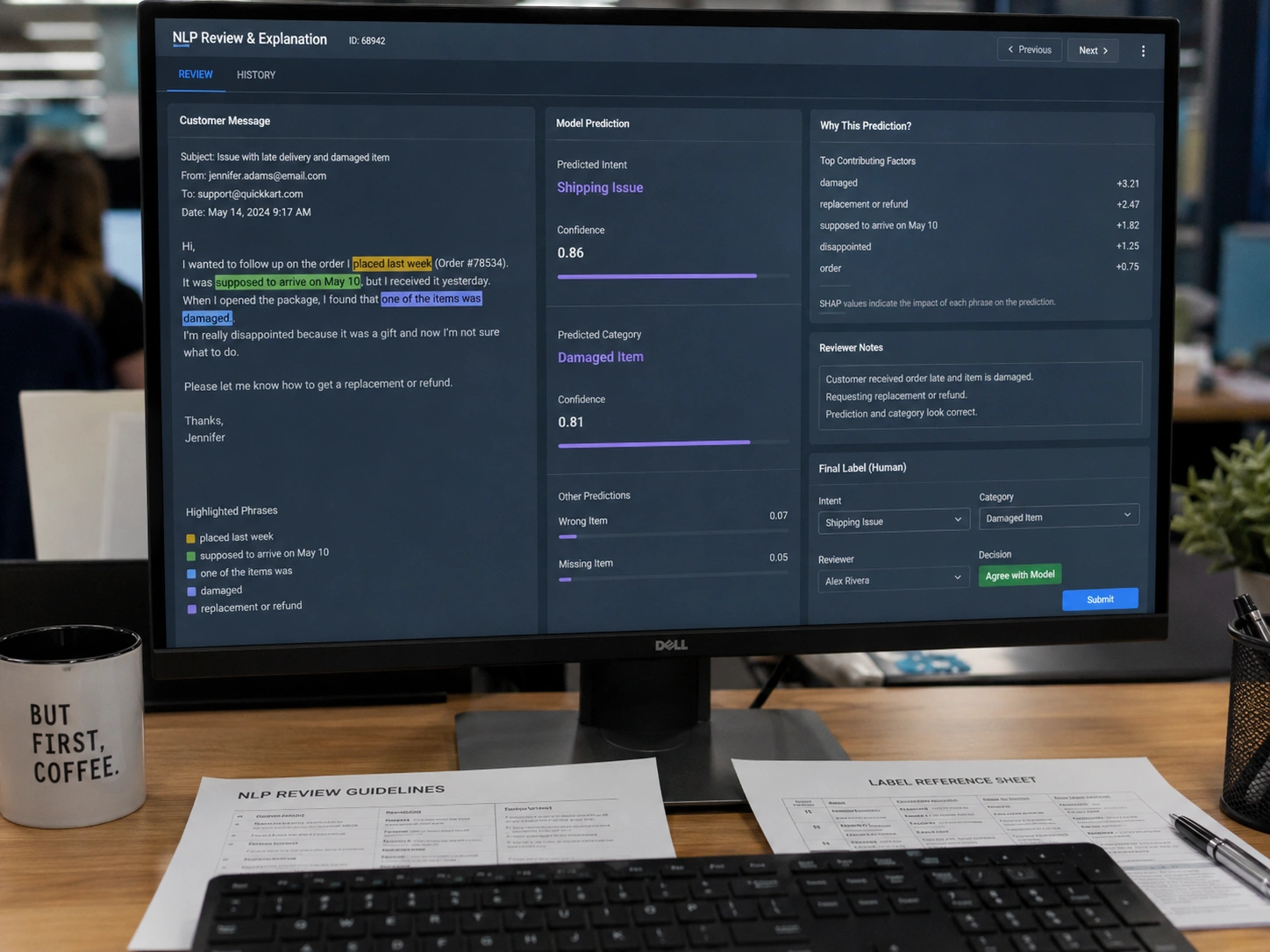
When the model misclassifies or misses a field, we look at why — which categories it confuses, which inputs trip it up — instead of treating the output as final. That error analysis is where most of the real accuracy gains come from, and it's exactly what black-box tools can't offer you.
Fixing an error has known levers: more labelled examples of the failing case, model tuning, or a targeted rule for a stubborn pattern. We build those correction paths in, so a wrong answer becomes a fixable input rather than a permanent flaw you live with.
The system flags low-confidence outputs for human review instead of pushing them through silently. People spend their time only on the genuinely ambiguous items, the rest runs automatically, and the corrections feed straight back into improving the model.
Because we build with measurement and correction in mind, you're never locked into a vendor's opaque box — the model, evaluation set, and pipeline are yours to run, audit, and keep improving. Explainability isn't a compliance checkbox; it's what makes NLP a long-term asset.
Weeks 1–2
We define the NLP tasks, accuracy targets, and volumes — and choose the right approach for each — before any build begins.
Weeks 3–5
We prepare the data and build the model foundation — labelling, training, or prompting — that determines accuracy.
Weeks 5–8
We build the production text pipeline and connect it to your systems and data sources.
Weeks 8–9
We measure accuracy on your labelled data, tune for cost and latency, and harden the system for production.
Weeks 9–12
We launch a controlled pilot, improve on real text, and move the system into production with monitoring and support.
Book a free 30-minute discovery call with a senior AI engineer — no slide deck, just questions about your text, your data, and your goals.
Enabled users to retrieve operational, financial, and project insights through natural language queries, transforming complex data analysis into instant, self-service intelligence.
See case studyWe build NLP on a proven stack — classical NLP libraries, transformer models, LLMs, vector databases, and deployment infrastructure — selecting the right combination for your text, accuracy targets, and cost requirements.
State-of-the-art models for reasoning, generation, and tool use.
Coordinate NLP pipelines, models, and tools with reliability and control.
High-performance vector databases for semantic search and retrieval.
Store and manage embeddings, features, and processing state for NLP.
Modern languages and runtimes for building AI applications.
Connect to tools, APIs, and external systems seamlessly.
Monitor, trace, and evaluate AI systems in production.
Enterprise-grade cloud services and infrastructure foundations.
Enterprises trust VOCSO for NLP systems built to scale securely and meet regulatory standards. We design text-processing systems that balance accuracy with privacy, PII handling, and compliance across AWS, Azure, and Google Cloud.

General Data Protection Regulation

Information Security Management Systems

System and Organization Controls
For AI applications in healthcare

Responsible AI principles and implementation

AI Risk Management

Principles and implementations
India’s personal data protection framework

Auditability frameworks

Standards and evaluation practices
Validate an AI agent use case with a low-risk, fixed-scope engagement designed to prove value, feasibility, and ROI before committing to a full build.
 Dedicated AI Team
Dedicated AI TeamA cross-functional AI agent team embedded into your environment — working within your processes, security requirements, and communication tools.
End-to-end delivery of a defined AI agent capability with fixed scope, timeline, and commercial terms. Full knowledge transfer and documentation included.
Let's discuss the right engagement model for your project?
Book a callFirst-hand experiences from firms that turned their text into data with NLP and achieved measurable results.
View all client testimonials“Vocso team has really creative folks and is very co-operative to implement client project expectations. MicroSave Consulting had great experience working with Anju and Prem.”

“Working with Deepak and his team at Vocso is always a pleasure. They employ talented staff and deliver professional quality work every time.”

“We love how our website turned out! Thank you so much VOCSO Digital Agency for all your hard work and dedication.”

“VOCSO SEO & SEM services helped me find new customers in a small budget. Their advanced SEO strategies made us visible to everyone.”

“Vocso team has really creative folks and is very co-operative to implement client project expectations. MicroSave Consulting had great experience working with Anju and Prem.”
“Working with Deepak and his team at Vocso is always a pleasure. They employ talented staff and deliver professional quality work every time.”
“We love how our website turned out! Thank you so much VOCSO Digital Agency for all your hard work and dedication.”
“VOCSO SEO & SEM services helped me find new customers in a small budget. Their advanced SEO strategies made us visible to everyone.”
The instinct now is to throw an LLM at every text problem. For a lot of production NLP, that's the expensive wrong answer — and knowing when is the most valuable thing we bring.
There's no single best tool, only the best tool for the task, the volume, and the budget. We choose deliberately rather than by default.
LLMs for hard and varied — Complex extraction, nuanced summarization, and tasks where labels are scarce play to an LLM's flexibility — worth the per-call cost at low-to-moderate volume.
Fine-tuned models for high volume — For classification, NER, or routing on millions of items, a fine-tuned transformer is usually faster, cheaper, and more consistent than an LLM call.
Classical NLP where it still wins — For well-defined, structured tasks, classical methods can be the most efficient and explainable option — no GPU bill, no latency tax.
Hybrid by design — Often the answer is both: an LLM to bootstrap labels and handle rare cases, a small model for the production workload.
At VOCSO, the model choice is made on benchmarked evidence — accuracy, latency, and cost per item on your data — not on whatever is fashionable that quarter.
Off-the-shelf NER finds people, places, and dates. It doesn't know your part numbers, your contract clauses, or your medical codes — and that's exactly what you need it to find.
Useful NER recognises the entities specific to your business, which generic models were never trained on. Getting there is a data-and-training problem, not a prompt.
Define your entity types — We work with you to specify the entities that matter — custom categories, not just generic labels — and what counts as a correct match.
Train on your vocabulary — We fine-tune on examples from your text so the model learns your domain's terms, abbreviations, and formats, not the open web's.
Handle the ambiguous cases — Real text is messy — overlapping entities, nested mentions, inconsistent formatting — and we design for those rather than the clean demo.
Validate and normalise — Extracted entities are validated and standardised (dates, amounts, IDs) so what comes out is clean, structured data your systems can use.
At VOCSO, NER is trained and measured on your domain's text — because an extractor that's accurate on generic benchmarks but wrong on your documents solves nothing.
A classifier that's 95% accurate in a notebook can quietly fall apart in production — on text it never saw, categories that drift, and classes it rarely encountered in training.
Production-grade classification is about robustness, not just a headline accuracy number on a tidy test split.
Represent the real distribution — We train and test on text that reflects production reality, including the rare classes and messy inputs, not a cleaned-up sample.
Handle class imbalance — When some categories are rare, naive accuracy lies. We use the right metrics and techniques so the model performs on the classes that matter, not just the common ones.
Confidence and abstention — The classifier flags low-confidence cases for human review instead of forcing a guess — so the automated decisions you keep are the ones you can trust.
Monitor for drift — Language and categories change; we monitor accuracy in production and re-train before quality silently degrades.
At VOCSO, classifiers are built and measured for the messy reality of production text — because the accuracy that matters is the one on next month's data, not last month's test set.
'Accuracy' alone hides the trade-off that actually matters in NLP: is it worse to miss a positive, or to flag a false one? Precision and recall make that explicit — and the right balance is a business decision.
Evaluating NLP properly means measuring the right metric for the task and tuning to the cost of each kind of error.
Precision vs. recall trade-off — Missing a fraud signal and flagging a clean transaction have very different costs. We tune the model to the balance your use case actually needs, not a generic default.
The right metric per task — F1, precision@k, macro vs. micro averages — we pick metrics that reflect real performance, especially where classes are imbalanced and plain accuracy misleads.
Error analysis, not just a score — We look at where and why the model fails, because the pattern of errors tells you how to fix it — more data, tuning, or rules.
A benchmark you keep — The labelled evaluation set becomes a lasting asset: every future change is measured against it, so improvements are provable and regressions are caught.
No VOCSO NLP system ships without an evaluation benchmark on your data — and we set the precision/recall target with you, in business terms, before we build.
The point of most NLP isn't text in, text out — it's text in, clean data out. Extraction that returns inconsistent or unvalidated fields just moves the mess downstream.
Reliable extraction means the output is structured, validated, and safe for the next system to consume without a human checking each one.
Define the target schema — We specify exactly what fields to extract and their types, so the output is predictable and your downstream systems know what to expect.
Validate before output — Extracted values are checked against the schema and business rules — a date is a valid date, an amount is a number — so malformed data never flows on.
Confidence and review routing — Low-confidence extractions are flagged for human review rather than passed through as fact, so the automated results you trust are genuinely reliable.
Handle missing and ambiguous — When a field isn't present, the system says so explicitly instead of inventing a value — a known gap is safer than a confident wrong answer.
At VOCSO, extraction is engineered to produce validated, structured data — because the value of NLP is realised only when the output is clean enough to act on automatically.
An NLP model that works on a hundred documents and one that processes ten million are different engineering problems. At scale, cost-per-item and latency stop being details and become the whole question of whether the project is viable.
Production NLP is as much about efficient infrastructure as it is about model accuracy. We engineer for the volume you actually run.
Right-size the model — A smaller fine-tuned model that hits the accuracy bar beats a huge one that exceeds it at ten times the cost. We pick the smallest model that does the job.
Batch and stream appropriately — High-volume backlogs run as efficient batch jobs; live inputs run in real time. Matching the processing mode to the need controls both cost and latency.
Cache and deduplicate — Repeated or near-identical text doesn't need re-processing every time; caching and deduplication cut wasted compute on real-world data that repeats more than you'd think.
Self-host where it pays — At high volume, running a fine-tuned model on your own infrastructure is often far cheaper than per-call API pricing — and we'll model the break-even with you.
At VOCSO, cost and latency are designed in from the start — because an NLP system that's accurate but too expensive or too slow to run at your volume never makes it to production.
You delivered exactly what you said you would in exactly the budget and in exactly the timeline.





Most teams start with one high-value task — classification, entity extraction, or sentiment on text they already have. We help you scope, build, and prove it in 6 weeks, with accuracy measured against a target. No open-ended contracts. No ambiguous scope.
deepak@vocso.com — no forms, no funnels.
It depends on the task, and getting this right is where most of the cost and accuracy is won or lost. LLMs are great for hard, varied, lower-volume work and where you lack labels. For high-volume, well-defined tasks — classification, NER, routing on millions of items — a fine-tuned smaller model is usually faster, cheaper, and more consistent. We benchmark both on your data and recommend the one that hits your accuracy target most economically; often the answer is a hybrid that uses an LLM only for the hard cases.
Cost depends on the task, data readiness, and volume. A focused single-task NLP system typically runs $15,000–$40,000; a multi-task system with custom model training, integration, and a production pipeline runs $40,000–$120,000+. We usually start with a fixed-price PoC (typically $12,000–$20,000) that proves accuracy on your real text before you commit, and every engagement opens with a free 30-minute discovery call. We also model cost-per-item, not just build cost, so you know what running it will cost at volume.
A production NLP system typically takes 10–14 weeks: roughly 2 weeks discovery and task definition, 5–6 weeks data preparation and model build, 2 weeks accuracy and hardening, then pilot and production. A scoped PoC runs in about 6 weeks. The biggest variable is labelled data — if you have good labels it's fast; if not, we build a labelling strategy into the timeline rather than letting it block you.
For supervised tasks (most classification and NER), yes — but you rarely need as much as you fear, and you often don't need it upfront. We assess what you have and design the cheapest path to enough: using an LLM to bootstrap labels that humans correct, active learning to label only the most useful examples, or a focused labelling effort. We won't let a lack of perfect data block the project, and every label you produce becomes a reusable asset.
Accuracy depends on the task and your data, so we measure it on a labelled sample of your text — precision, recall, and F1 — and agree a target with you before building, tuning to the precision/recall balance your use case needs rather than promising a vague number. It doesn't stop at launch: language and categories drift, so we monitor accuracy in production against your benchmark and re-train or tune before quality degrades. The labelled evaluation set we build is the asset that makes every future improvement measurable.
By matching the model to the volume and engineering the pipeline. For high-volume tasks we use right-sized fine-tuned models (often far cheaper than per-call LLM pricing), batch processing, caching, and deduplication, and we self-host where that's more economical. We model cost-per-item from the start so the system is viable at your real volume — not just in the pilot.
Yes. We combine document parsing and OCR (for scans) with NLP extraction to pull structured fields from PDFs, forms, contracts, and reports — validated against a schema so the output is clean data, not raw text. Messy real-world documents are exactly what we engineer for.
Yes. NLP pipelines connect to your databases, document stores, CRMs, and data warehouses, and output structured data to wherever it needs to go. We support both batch processing (for backlogs) and real-time processing (for live inputs), integrated into your existing workflows so the results land where work actually happens.
Often, yes. If you have a classifier or extraction system that's underperforming or too expensive to run, we assess it and frequently improve accuracy or cut cost — better data, a right-sized model, tuning, or a hybrid approach — rather than rebuilding from scratch. Sometimes a fresh build is cheaper; we'll tell you honestly which.
Yes. We handle PII detection and redaction, keep data within your required perimeter (including fully self-hosted deployments), encrypt data, and log processing for audit — supporting GDPR, HIPAA, and ISO 27001 requirements depending on your context. For sensitive text we can run entirely in your environment so data never leaves it.
Yes. Every engagement includes 90 days of post-launch support — accuracy monitoring, tuning, and adjustments. Beyond that we offer retainers covering ongoing monitoring, re-training as your text and categories evolve, new tasks, and pipeline maintenance, because an unmaintained NLP model slowly drifts out of accuracy.
Completely. The trained models, code, pipelines, labelled datasets, and documentation are yours, unconditionally — including any custom models trained on your data, which are a lasting asset. We sign NDAs before any discovery conversation, retain no client data after a project concludes, and never use your data to train models for anyone else.
Discover complementary services that pair with your NLP — from machine learning and LLM apps to RAG, chatbots, and data analytics.