The right agency for your project providing success with every solution
600+
Project completed


Build intelligent AI apps that retrieve, reason, and respond using your private data with custom Retrieval-Augmented Generation solutions with VOCSO.


Project completed

Design and implement tailored RAG workflows combining vector search, retrievers, and LLMs for your use case.

Extract, clean, and embed knowledge from PDFs, DOCs, websites, and structured data sources.

Seamlessly connect Retrieval layer with top LLMs and manage prompt engineering.

We optimize retrieval logic and scoring algorithms to ensure your RAG system surfaces the most contextually relevant results—every time.

Set up scalable vector search infrastructure to store and retrieve embeddings effectively.
Build powerful, backend-driven applications with our expert Python development services—flexible, efficient, and built to scale.
VOCSO builds interactive, responsive interfaces using ReactJS, AngularJS, VueJS, TezJS, and CSS. Our services include UI/UX design, SPAs, PWAs, and more — crafted for great user experiences. Connect internal databases, documents, APIs, and CRMs with RAG systems for contextual accuracy.

Enable your RAG system to query and retrieve insights directly from relational and NoSQL databases (e.g., PostgreSQL, MySQL, MongoDB, etc.) using natural language query.

Build intelligent, domain-aware chatbots that provide real-time, source-backed answers.

We craft and fine-tune prompts that guide large language models to generate precise, domain-specific responses based on your retrieved data.

Our experts offer hands-on training and strategic consulting to help your teams successfully implement, scale, and extract maximum value from RAG technology in line with your business goals.
At VOCSO, We develop secure, scalable, and high performance back-end to power your web and mobile apps — ensuring speed, stability, and seamless integration.
From concept to launch, VOCSO builds mobile apps that drive engagement and revenue — covering front-end, back-end, and middleware.
 Dedicated Resources/ Team Hiring
Dedicated Resources/ Team HiringWith a Dedicated Team of experienced RAG Developers at your disposal, you control the whole development experience.
 Fixed Cost
Fixed CostThis model provides cost predictability and is ideal for well-defined projects with a clear scope, where changes are minimized, and the project stays within a fixed budget
 Time & Resources Based (Pay As You Go)
Time & Resources Based (Pay As You Go)You pay as you go, leveraging a flexible approach where you're billed for actual hours spent by our RAG developers.
Let's discuss the right engagement model for your project?
Schedule a call
The client sought a comprehensive system for aggregating tee times available for sale across multiple golf clubs, each using different tee time booking software systems. The primary challenge was interfacing with these diverse systems. The objective was to create a solution capable of real-time searching, finding, and aggregating tee times available for sale and those sold within a specific time window. This platform served over 1,000 golf courses, enabling them to showcase their tee times and drive sales while effectively tracking transactions.


In pursuit of a more streamlined and efficient job application system, the client initiated a pivotal project aimed at the development of a feature-rich custom jobs module. The objective was to seamlessly integrate this module into their existing job application workflow. Achieving this ambitious goal hinged on the successful implementation of a robust full stack development strategy and effective API integration.

"Vocso team has really creative folks and is very co-operative to implement client project expectations. MicroSave Consulting had great experience working with Anju and Prem."

"Working with Deepak and his team at Vocso is always a pleasure. They employ talented staff and deliver professional quality work every time."


"I am working with VOCSO team since about 2019. VOCSO SEO & SEM services helping me to find new customers in a small budget. Again thanks to VOCSO team for their advanced SEO optimization strategies, we are now visible to everyone."

"We love how our website turned out! Thank you so much VOCSO Digital Agency for all your hard work and dedication. It was such a pleasure working with the team!"

"It was an amazing experience working with the VOCSO team. They were all so creative, innovative, and helpful! The finished product is great as well - I couldn't have done it without them"

"I want to take a min and talk about Deepak and Vocso team.We have outsourced web projects to many offshore companies but found Deepak understands the web content management and culture of US based firm and delivered the project with in time/budget . Also in terms of quality of product exceeds then anything else on which we work on offshore association I would recommend them for any web projects."

"Hi would like to appreciate & thanks Deepak & Manoj for the assistance any one thats look in to get web design They are very efficient people who can convert a little opportunity to fruitful association."

Understand your requirements and agree on commercials.
Based on thorough discussion and strategy

Add functionalities with plugins and customization
Make your website business ready
Perform complete quality checks and go live
Let's find out the right resources for you
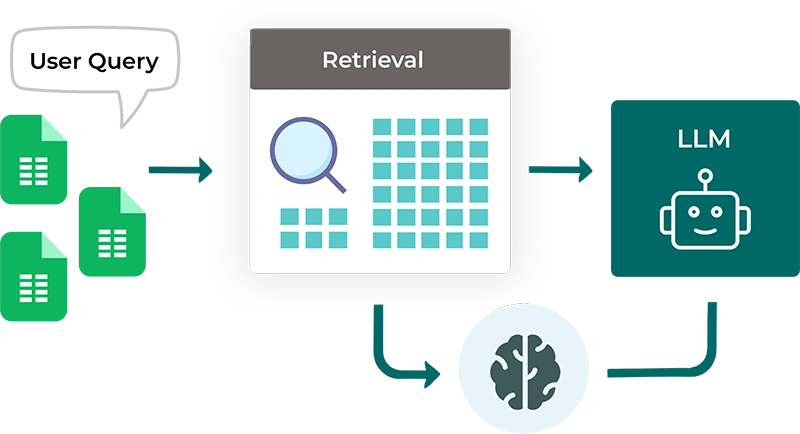
Schedule a callRAG is a cutting-edge AI framework that improves the accuracy and contextual relevance of responses generated by large language models (LLMs). Instead of relying only on what the model was trained on, RAG dynamically pulls in external data—such as internal documents, databases, or APIs—at the time of generating responses. This not only removes hallucinations but also ensures that the output is based on the facts and tailored to your business.
Retrieval : Fetching relevant information from external or private data sources based on the user’s query.s
Augmented : Enhancing the model's understanding by injecting real-time, context-rich data into the response pipeline.
Generation : Producing coherent, natural language responses by combining user input with the retrieved information.
Retriever : Identifies and fetches relevant content from structured or unstructured data sources.
Vector Database : Stores embeddings for efficient similarity search (e.g., FAISS, Pinecone, Weaviate).
Embedding Model : Converts text into dense vector representations for semantic retrieval.
LLM (Large Language Model) : Generates natural language output based on retrieved content and user query.
Prompt Engineering Layer : Structures and optimizes the input given to the LLM for accurate, contextual responses.
Data Preprocessing & Chunking : Splits and cleans documents or records into manageable, searchable segments.
Reranker (Optional) : Improves retrieval accuracy by reordering results based on deeper context matching.
Access Control / Personalization Layer : Filters retrieved content based on user roles, permissions, or session context.
Monitoring & Evaluation Module : Tracks performance metrics like retrieval precision, latency, and hallucination rates.
RAG systems rely on a smartly aligned retrieval, embedding, and generation modules. Below are the most popular frameworks and libraries we use to build scalable, production-ready Retrieval-Augmented Generation pipelines:
LangChain : The most widely adopted framework for chaining together retrievers, vector databases, prompts, and LLMs.
LlamaIndex (formerly GPT Index) : Designed to index and retrieve structured and unstructured data for seamless integration with LLMs.
Haystack by deepset : A robust framework for building end-to-end RAG applications, including document retrieval, pipelines, and evaluation.
Hugging Face Transformers : Provides access to a wide range of open-source LLMs and embedding models, ideal for custom RAG setups.
RAG Implementation from Facebook AI :The original research-backed PyTorch implementation combines dense retrievers with generative models.
At VOCSO, we closely research the need of the project to decide which framework, ai models and set of libraries are appropriate.
Vector databases power the retrieval layer in RAG systems by storing and searching through embeddings—delivering fast, context-aware results based on semantic similarity.
FAISS : Fast and efficient for in-memory similarity search.
Pinecone : Scalable, fully managed, and built for production workloads.
Weaviate : Schema-aware, with hybrid search and metadata filtering.
Qdrant :High-performance with advanced filtering and open-source flexibility.
ChromaDB :Lightweight and ideal for prototypes and quick iterations
We help you choose and implement the right vector store for your speed, scale, and security needs.
Prompt engineering plays a critical role in ensuring your RAG system delivers relevant, accurate, and context-aware outputs. It defines how the language model interprets retrieved data and transforms it into meaningful responses.
Structuring prompts that align with your business logic and domain
Minimizing and possibly remove hallucinations by guiding the LLM to focus on retrieved content
Controlling tone, format, and output structure
Enabling adaptive, multi-turn interactions through dynamic prompt design
With the right prompt strategy, your AI doesn’t just respond—it understands.
You delivered exactly what you said you would in exactly the budget and in exactly the timeline.





RAG is an AI architecture that enhances large language models by retrieving relevant information from external sources before generating a response. This makes the output more accurate, up-to-date, and context-aware. This does a huge favour by not having to deal with retraining a language model again and again with our specific data.
Yes. RAG can be customized with data relevant to your industry and business — whether it's medical reports, legal documents, or internal company files—making the output more meaningful, compliant, and tailored to your audience.
Unlike standard LLMs, which rely solely on pre-trained knowledge, RAG systems fetch real-time data from connected sources—documents, databases, APIs—to provide grounded and domain-specific responses.
RAG is making a mark across sectors
In healthcare, it's helping doctors access updated research.
In finance, it’s used for fast document analysis.
In retail, it enhances chatbot accuracy.
In corporate settings, it turns static knowledge bases into intelligent assistants.
A RAG system usually includes:
A Retriever to find the right documents
An Encoder to turn queries into searchable data
A Generator that crafts the final output using the retrieved content
Optionally, a Memory Layer for tracking past conversations
RAG can fetch content from almost any digital source:
Structured Data sources ( SQL, NoSQL)
Unstructured Documents ( PDFs & Word documents )
Blogs & websites
Cloud storage
Company intranets
API-driven knowledge sources
No. RAG allows you to use existing pre-trained LLMs (like OpenAI, Claude, Cohere) and simply augment them with your data. This saves time and cost.
At VOCSO, we ensure that all retrieval layers are secured with access control, encryption, and compliance best practices—so your data never leaves your trusted environment.
We use LangChain, LlamaIndex, FAISS, Pinecone, Weaviate, OpenAI, and other top-tier tools to build reliable and scalable RAG pipelines.
Timelines vary by complexity, but most MVPs can be delivered in 3–6 weeks. We offer tailored implementation plans based on your data and use case.
Absolutely. We can embed RAG into your CRM, support platform, dashboard, internal tools, or web/mobile apps via secure APIs.




