15+ Years
Enterprise software delivery since 2009 — a track record built across technology cycles, not just the current AI wave.


The hard part of computer vision was never the demo — it's the dim warehouse, the tilted camera, and the defect the model has never seen. We build vision that survives your real conditions: object detection, visual inspection, OCR, and video analytics, trained on your images, deployed where the cameras actually are (edge or cloud), and tuned to the error trade-off your operation can live with. Measured on your footage, not a benchmark.


A decade of AI engineering experience, validated in numbers

Computer vision is applied machine learning — the same training, evaluation, and MLOps discipline behind every model we build, for prediction and classification beyond vision too.

Wire vision outputs into the systems that act on them — MES, ERP, WMS, ticketing, dashboards — so a detection becomes a recorded event, an alert, or a workflow, not just a bounding box.

When seeing something should trigger action — stop the line, raise a ticket, dispatch a crew — agents that act on what vision detects rather than just reporting it.
OCR gets you the text; NLP makes sense of it — classification, extraction, and validation that turn read characters into structured, usable fields for document AI.
Synthetic images to cover rare cases, augmentation, and multimodal models — generative techniques that strengthen a vision system exactly where real data is scarce.

Turn a visual event into an end-to-end automated process — an inspection result routes the part, a zone breach escalates, a count updates inventory, no human in the middle.

Not sure your imagery is ready, or where vision pays off first? Strategy and a costed roadmap that sequences the work before you build.
Search and retrieve across visual documents and scanned archives — combine OCR with retrieval so people find the right image or page by meaning, not filename.

Automated quality control that spots defects, damage, and anomalies on the line or on site — catching what tired eyes miss, consistently, at the speed of production.

Read text from images, scans, and photos — invoices, forms, IDs, labels, handwritten notes — and extract it as structured, validated data, even from imperfect real-world captures.

Find and label what's in an image or frame — products, parts, people, defects — and sort images into your categories, with the accuracy and speed production volumes demand.
Our computer vision is tailored to the specific imagery, environments, and accuracy requirements of each industry.
Consulting & Advisory Automate document and image processing — OCR, classification, and extraction from the scanned material consulting firms handle.
Trusted by Rodic Consultants
SaaS & Digital Platforms. Add vision features to your product — image moderation, tagging, and visual search — at the scale your users upload.
Engineering & Infrastructure. Automate site inspection, defect detection, and progress monitoring from photos, drone footage, and drawings.
Financial Services. OCR and document AI for KYC, cheque, and form processing — extracting and verifying data from images at volume.
Supply Chain & Logistics. Read labels, count items, and inspect packages with vision across the warehouse and in transit.
Healthcare & Research. Vision for medical-imaging support, sample analysis, and research image processing — with strict data controls and human oversight on every result.
CleanTech & Mobility. Inspect panels, infrastructure, and fleet condition from imagery and drone footage across energy and mobility assets.
EdTech Platforms. Process handwritten answers, support exam proctoring, and analyse visual learning content with computer vision.
Non-Profits & Foundations Digitise documents, analyse field imagery, and verify impact from photos to stretch small teams.








We combine deep computer-vision and machine-learning expertise with enterprise delivery practices to ship vision systems that are accurate, fast, and reliable in the real world.
Enterprise software delivery since 2009 — a track record built across technology cycles, not just the current AI wave.
Independently certified, annually audited — meets the security baseline enterprise procurement actually checks.

Nine in ten enterprise clients return for follow-on work — the only measure of delivery quality that cannot be faked.

Verified client reviews, independently collected — real feedback from real enterprise engagements.

Certified cloud partnerships with AWS and Microsoft Azure — enterprise infrastructure standards from day one.

DataSense, DocSense, BidSense — proprietary pre-built AI products that go live in weeks, not months of custom build.

IP, data, and strategy protected before the first discovery call ends — not after contracts are signed.

Post-deployment optimisation included in every engagement — we stay accountable until the system is performing.

A model that scores 99% on a clean, well-lit test set is easy. The same model in a dim warehouse, on a tilted camera, on parts it's never seen, is where most projects quietly fall apart. Here are the truths that separate computer vision that survives real footage from a demo reel that never ships.
The benchmark accuracy a vendor quotes was measured on images chosen to look good. Your cameras, your lighting, your angles, and the objects you actually photograph are a different distribution entirely — and that gap, not the model architecture, is where computer vision projects live or die.

A model that scores 99% on a tidy public dataset can crater on your footage — different lighting, dust on the lens, motion blur, a tilted camera, parts it never saw in training. The demo proved the task is possible in ideal conditions; it said nothing about whether it works in yours, which is the only question that matters.
Production vision that lasts is built on data collected from your real conditions, evaluation against your real failure cases, and deliberate robustness to the variation a live environment throws up. Projects fail when they skip that work and assume the demo's accuracy will follow them into the warehouse. It won't.
The most revealing question you can ask a vision vendor isn't about accuracy — it's "show me where your model breaks, and what you did about it." A partner who has done the real work has a stack of hard cases and fixes. One who only has a polished demo is about to discover your conditions on your budget.
A pretrained model is excellent at recognising cars, people, and cats — and useless at spotting the specific defect on your component, the field on your form, or the event on your site. The value isn't in the generic model; it's in teaching it what matters to you.

The hard, valuable tasks are domain-specific: this hairline crack versus that acceptable scratch, this product on the shelf versus a competitor's, this signature field on your particular form. None of that is in a model trained on internet images, which is why a vendor who never asks to see your images is a red flag.
We adapt models to your domain — fine-tuning on your parts, defects, documents, and conditions so the system recognises what your operation actually cares about, at the accuracy your operation actually needs. The pretrained model is a starting point, not the product.
Public datasets have thousands of examples per class. The defect you care about might appear once in ten thousand items — so the model has to learn it from far fewer examples, which takes technique, not just more compute. Handling that scarcity well is most of the skill in industrial vision.
Critical information sits in photos, scans, and forms no system can read, so it's keyed in by hand or never captured at all. Domain-trained OCR and vision turn that imagery into structured data automatically — unlocking what was effectively invisible to your software.
"95% accurate" is a number that hides the decision that actually matters. In inspection, letting a bad part through and flagging a good one as bad have wildly different costs — and which mistake your model makes is something you tune, not something you accept.

Two models can both be "95% accurate" while one waves bad parts through and the other rejects good ones constantly. A single headline figure tells you nothing about which failure you're buying — so we measure precision and recall separately and show you both, because that's where the real cost lives.
A missed crack in a safety part and a false reject on a cheap item are not equal mistakes. We tune the model's threshold to the trade-off your operation can actually live with — catching every defect even at the cost of some false alarms where safety dominates, or minimising false rejects where throughput does.
The model doesn't have to decide everything. We route low-confidence detections to a person, so the system auto-handles the clear cases and escalates the genuinely ambiguous ones — getting most of the labour saving without betting a critical call on a borderline prediction.
The only error rates that mean anything are the ones measured on your footage, including the hard cases. We benchmark against a labelled set from your real conditions and report honest numbers — so you know what you're deploying before it's on the line, not after.
The defect, the safety breach, the fraud — the thing you actually want vision to catch — is usually the rarest thing in your data. You can have a million images and still only a handful of the case that matters, and that scarcity is the real challenge in most vision projects.

A production line produces thousands of acceptable items for every defective one, so your data is wildly imbalanced toward the case you don't care about. A naive model can hit high accuracy by simply never flagging anything — and miss every defect while looking great on paper. We design and measure specifically against that trap.
Getting enough examples of the rare case takes a plan: targeted collection, augmentation, synthetic data, and careful annotation of the events when they do occur. We assess what you have and design the cheapest path to enough of the cases that actually make or break accuracy.
Images have to come from the cameras, lighting, and angles you'll actually run in — a model trained on clean studio shots fails on the gritty reality of your site. Part of readiness is making sure the training data looks like production, not like a brochure.
A data gap isn't a reason to wait. Start with one well-defined visual task in one environment with a clear accuracy target — one defect type, one camera, one document. That first working model proves value, and the images it sees in production become the dataset that improves it and seeds the next.
A model that needs a cloud round-trip is useless on a production line that needs an answer in milliseconds, on-site. Where a vision model runs — edge, camera, or cloud — is as big a design decision as its accuracy, and getting it wrong makes a good model undeployable.

On a production line, a remote site, or anywhere with poor connectivity, the model must run locally — on a device or camera — for real-time results and to keep footage on-site. Edge avoids the latency and bandwidth of shipping every frame to the cloud, but means smaller, optimised models and real hardware constraints.
For heavier models, lower frame volumes, or images that already live in the cloud, cloud deployment is simpler and more flexible — easier to update, scale, and monitor, with no hardware to manage in the field. The cost is latency, bandwidth, and an ongoing per-image bill that grows with volume.
Accuracy, speed, connectivity, privacy, and cost pull in different directions, so we weigh them for your specific case rather than defaulting to whatever's easiest to build. The right answer for a connected warehouse is rarely the right answer for an offline rural site.
Many systems split the work: a fast model on the edge for the common case and real-time response, with harder cases or aggregate analytics in the cloud. We design that split deliberately, so you get edge responsiveness where milliseconds matter and cloud flexibility where they don't.
A vision system isn't done at launch. A new camera, a seasonal change in light, a redesigned product, a dirty lens — any of these can quietly erode accuracy on a model that was perfect on day one. Vision that lasts is monitored and maintained, not installed and forgotten.
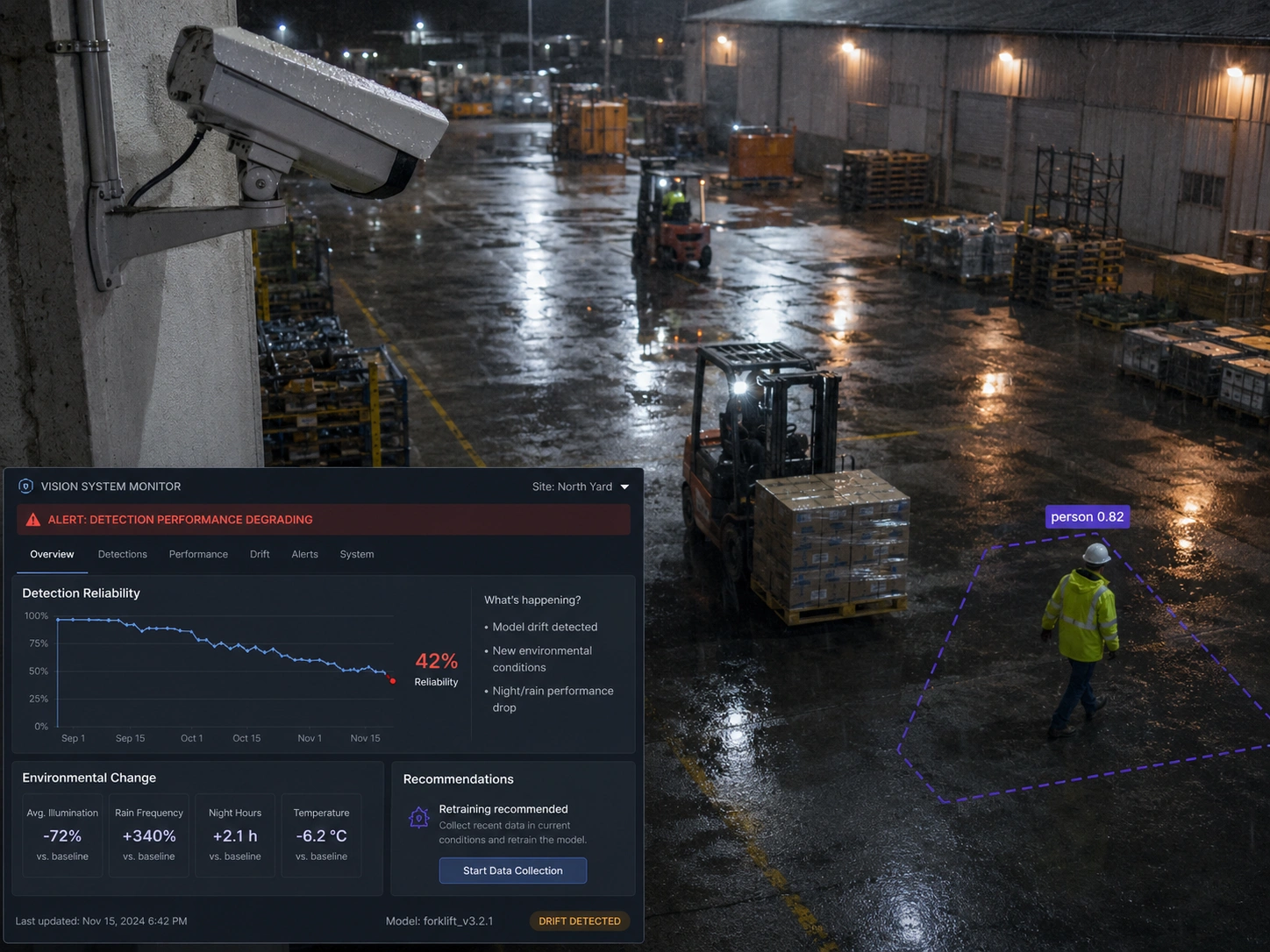
The conditions a model was trained on don't stay frozen. Lighting shifts with the seasons, cameras get replaced or nudged, products get redesigned, packaging changes — and each gap between training and reality chips away at accuracy. The decline is gradual and silent, which is what makes it dangerous.
Without monitoring, the first sign of a degraded model is a missed defect or a flood of false alarms in production. We track accuracy against a benchmark over time so quality is a number you can see falling — and act on — before it becomes an incident.
When drift shows up, the fix is more data from the new conditions and a retrain — so we build the capture-and-retrain loop in from the start rather than bolting it on after the first failure. The production images the system sees become the fuel that keeps it accurate.
Because maintenance is built in, you're never stranded with a black box you can't update. The model, training pipeline, and evaluation set are yours to run and improve — so the system stays accurate for years, not just through the warranty period.
Weeks 1–2
We define the visual tasks, conditions, and where the model must run — and assess your image data — before any build begins.
Weeks 3–5
We prepare and annotate the image data and build the model foundation — training or fine-tuning — that determines accuracy.
Weeks 5–8
We build the vision pipeline and deploy it where the cameras are — edge, on-device, or cloud.
Weeks 8–9
We measure accuracy on your images, tune the error trade-off, and harden the system for real-world conditions.
Weeks 9–12
We launch a controlled pilot, improve on real footage, and move the system into production with monitoring and support.
Book a free 30-minute discovery call with a senior AI engineer — no slide deck, just questions about your images, your environment, and your goals.
Enabled users to retrieve operational, financial, and project insights through natural language queries, transforming complex data analysis into instant, self-service intelligence.
See case studyWe build computer vision on a proven stack — vision libraries and detection frameworks, deep-learning training tools, edge runtimes, and cloud deployment infrastructure — selecting the right combination for your images, accuracy targets, and where the model has to run.
State-of-the-art models for reasoning, generation, and tool use.
Coordinate vision pipelines, models, and tools with reliability and control.
High-performance vector databases for semantic search and retrieval.
Store and manage image embeddings, features, and processing state.
Modern languages and runtimes for building AI applications.
Connect to tools, APIs, and external systems seamlessly.
Monitor, trace, and evaluate AI systems in production.
Enterprise-grade cloud services and infrastructure foundations.
Enterprises trust VOCSO for computer vision built to scale securely and meet regulatory standards. We design vision systems that balance accuracy with privacy, data protection, and compliance across AWS, Azure, Google Cloud, and the edge.

General Data Protection Regulation

Information Security Management Systems

System and Organization Controls
For AI applications in healthcare

Responsible AI principles and implementation

AI Risk Management

Principles and implementations
India’s personal data protection framework

Auditability frameworks

Standards and evaluation practices
Validate an AI agent use case with a low-risk, fixed-scope engagement designed to prove value, feasibility, and ROI before committing to a full build.
 Dedicated AI Team
Dedicated AI TeamA cross-functional AI agent team embedded into your environment — working within your processes, security requirements, and communication tools.
End-to-end delivery of a defined AI agent capability with fixed scope, timeline, and commercial terms. Full knowledge transfer and documentation included.
Let's discuss the right engagement model for your project?
Book a callFirst-hand experiences from firms that put computer vision to work and achieved measurable results.
View all client testimonials“Vocso team has really creative folks and is very co-operative to implement client project expectations. MicroSave Consulting had great experience working with Anju and Prem.”

“Working with Deepak and his team at Vocso is always a pleasure. They employ talented staff and deliver professional quality work every time.”

“We love how our website turned out! Thank you so much VOCSO Digital Agency for all your hard work and dedication.”

“VOCSO SEO & SEM services helped me find new customers in a small budget. Their advanced SEO strategies made us visible to everyone.”

“Vocso team has really creative folks and is very co-operative to implement client project expectations. MicroSave Consulting had great experience working with Anju and Prem.”
“Working with Deepak and his team at Vocso is always a pleasure. They employ talented staff and deliver professional quality work every time.”
“We love how our website turned out! Thank you so much VOCSO Digital Agency for all your hard work and dedication.”
“VOCSO SEO & SEM services helped me find new customers in a small budget. Their advanced SEO strategies made us visible to everyone.”
The single biggest reason vision projects fail is the gap between the images a model was trained on and the images it meets in production — different lighting, angles, cameras, and conditions.
Real-world robustness isn't an accident; it's engineered. A model that only works on clean images is a science project, not a product.
Train on real conditions — We gather images from your actual cameras, lighting, and angles — including the bad ones — so the model learns the conditions it will face, not idealised ones.
Augment for variation — We synthetically vary brightness, blur, rotation, and occlusion in training so the model generalises to conditions it hasn't literally seen.
Test against the hard cases — We evaluate on the difficult images — glare, partial views, unusual angles — not just the easy ones, because that's where production accuracy is won or lost.
Plan for the unexpected — The model flags low-confidence or out-of-distribution images for human review rather than guessing, so a strange input doesn't become a silent error.
At VOCSO, we build and test vision on the messiness of your real environment — because the only accuracy that matters is the accuracy on the images you'll actually process.
Half of getting computer vision right is framing the problem as the correct task. The same business goal can need very different vision approaches — and picking the wrong one wastes effort and data.
We map your goal to the right computer-vision task before any training, because the choice drives the data, the model, and the cost.
Classification — what is this? — Assigns a whole image to a category (pass/fail, product type). Simplest and cheapest when you only need a label per image.
Detection — what and where? — Locates and labels objects within an image with bounding boxes. Right when position, count, or multiple objects matter.
Segmentation — exactly which pixels? — Outlines regions at the pixel level. Needed for precise measurement, area, or boundary tasks — more powerful, but more data and compute.
OCR and beyond — Reading text, tracking across video, or estimating pose are distinct tasks again; we pick the one that matches the actual decision you need.
At VOCSO, we choose the simplest task that solves your problem — because over-specifying (segmentation when classification would do) burns data and budget for accuracy you don't need.
The most common blocker to a vision project is the same one everyone fears: 'we don't have thousands of labelled images.' You rarely need them — if you use the right techniques.
Modern computer vision has several ways to get to production accuracy without a massive hand-labelled dataset, and we use whichever fits your situation.
Transfer learning — We start from models pretrained on millions of images and fine-tune on your far smaller set, so you inherit general visual understanding and only teach the specifics.
Data augmentation — We multiply the value of each labelled image by varying it — crops, rotations, lighting — turning hundreds of images into effectively thousands.
Smart, focused labelling — Active learning points your labelling effort at the images that will improve the model most, so you label the few hundred that matter, not the thousands that don't.
Synthetic data where it helps — For rare defects or events, we can generate or simulate examples so the model sees enough of the cases it would otherwise almost never encounter.
At VOCSO, a thin dataset is a starting point, not a dead end — we design the cheapest path to the accuracy you need rather than waiting on a dataset you'll never finish.
A vision model is only useful where it can actually run. The deployment decision — edge or cloud — shapes the model, the cost, and whether the system is even feasible where your cameras are.
We make this call early, because it constrains everything downstream from model size to hardware.
Edge for real-time and on-site — On a line or remote location, the model runs on a device or camera for instant results, with no cloud round-trip and footage that stays local.
Cloud for heavy or flexible workloads — Larger models, lower volumes, or images already in the cloud favour cloud deployment — simpler to scale, update, and monitor.
Optimise for the target — Edge needs models compressed and accelerated to fit real hardware; we quantise and optimise so accuracy survives the shrink to a device.
Hybrid where it pays — A fast edge model for the common case plus cloud for the hard cases or analytics often beats either alone; we design the split deliberately.
At VOCSO, deployment is a first-class design decision — because a model that's accurate but can't run where the cameras are has solved nothing.
A single accuracy number is dangerous in computer vision, because it hides the question that actually matters: which kind of mistake are you making, and what does each one cost you?
In inspection and safety especially, a missed defect and a false alarm have wildly different consequences — and the right model is the one tuned to your trade-off.
Precision vs. recall — Missing a defect (low recall) versus flagging good items as bad (low precision) are different failures; we measure them separately and tune to which one you can least afford.
The right metric (mAP and friends) — For detection we use mean average precision and per-class metrics, so performance on the rare-but-critical class isn't hidden by the common ones.
Cost-weighted thresholds — We set the model's decision threshold to your real costs — when a missed defect is far more expensive than a re-check, we tune accordingly.
A benchmark on your images — The labelled evaluation set becomes a lasting asset: every model change is measured against it, so improvements are provable and regressions are caught.
No VOCSO vision model ships without an evaluation benchmark on your images — and we set the precision/recall target with you, in the terms of your operation, before we build.
Automated visual inspection is one of the highest-ROI uses of computer vision — and one of the easiest to get wrong, because real defects are varied, rare, and unforgiving of a model that only learned the obvious ones.
Inspection is where the discipline of real-world CV matters most: the cost of a miss is high, and the conditions are rarely ideal.
Capture defects, not just 'good' — The hardest part is gathering enough examples of real defects, which are rare by definition; we design the data strategy around exactly that problem.
Anomaly detection for the unknown — Some defects you've never seen before; we combine known-defect detection with anomaly detection so 'something is wrong here' is caught even without a labelled example.
Tune to the cost of a miss — A defect that reaches a customer usually costs far more than a false reject; we tune the model to err on the safe side for your specific economics.
Built for the line — Inspection runs at production speed, in production lighting, on production hardware — so we engineer for that throughput and those conditions, not a lab bench.
At VOCSO, visual inspection is engineered around the reality of defects and the line — because an inspector that only catches the easy flaws gives you false confidence, which is worse than none.
You delivered exactly what you said you would in exactly the budget and in exactly the timeline.





Most teams start with one high-value visual task — defect detection, OCR, or counting — on images they already capture. We help you scope, build, and prove it in 6 weeks, with accuracy measured against a target. No open-ended contracts. No ambiguous scope.
deepak@vocso.com — no forms, no funnels.
That's exactly what we engineer for, and it's the question that separates a demo from a product. We train on images from your actual cameras and conditions — including the bad ones — augment for variation, and test against the hard cases like glare, partial views, and odd angles. A model that only works on clean images isn't a product; real-world robustness is the whole job, so we measure it on your footage before promising anything.
Cost depends on the task, your image data, and deployment — edge adds work. A focused single-task CV system typically runs $20,000–$50,000; a multi-task or edge-deployed system with custom model training runs $50,000–$120,000+. We usually start with a fixed-price PoC (typically $12,000–$20,000) that proves accuracy on your real images first, and every engagement opens with a free 30-minute discovery call.
A production CV system typically takes 10–14 weeks: roughly 2 weeks discovery and image-data assessment, 5–6 weeks data annotation and model build, 2 weeks accuracy and hardening, then pilot and production. A scoped PoC runs in about 6 weeks. The biggest variables are image-data availability and edge deployment, both of which we scope upfront so the timeline is honest.
Yes — you rarely need as many as you fear. We use transfer learning (starting from models pretrained on millions of images), data augmentation, focused active-learning labelling, and synthetic data for the rare cases that are hardest to capture. We design the cheapest path to your accuracy target rather than waiting on a huge hand-labelled dataset, and the images the system sees in production become the dataset that improves it.
Accuracy depends on the task and image quality, so we measure it on a labelled set of your images — precision, recall, mAP — and set a target with you before building, tuning to the error trade-off your use case needs, because a missed defect and a false alarm rarely cost the same. It doesn't stop at launch: cameras move, lighting shifts, products change, so we monitor accuracy in production and re-train or tune before it degrades. The labelled evaluation set we build is what makes every change measurable.
Both — and we decide based on your needs. For real-time results, poor connectivity, or keeping footage on-site, we deploy optimised models on edge devices and cameras. For heavier models or lower volumes, cloud is simpler. Many systems are hybrid — a fast edge model plus cloud for hard cases. We optimise (quantise, compress) so accuracy survives the move to a device rather than collapsing on it.
Yes — it's one of our highest-value use cases. We build inspection that catches defects, damage, and anomalies at production speed, including anomaly detection for defects you've never labelled. We tune it to the cost of a miss versus a false reject, and engineer it for your line speed, lighting, and hardware — not a lab bench.
Both. We build OCR and document AI that extracts text and fields from photos, scans, forms, IDs, labels, and even handwriting — validated against a schema so the output is structured, usable data, even from messy captures (skew, glare, low resolution) that off-the-shelf OCR struggles with. And we build video analytics for counting, tracking objects or people, and detecting events and movement in real time, turning live or recorded feeds into metrics and alerts.
Usually, yes. We can run vision on the feeds from cameras and CCTV you already have, turning existing hardware into a sensing layer for inspection, safety, or counting — no need to rip out and replace, provided the image quality and placement support the task, which we assess upfront rather than after install.
Carefully and by design. We can run entirely on the edge so footage never leaves your site, blur or avoid storing identifiable faces where the task doesn't need them, encrypt data, and restrict and log access — aligning to GDPR, HIPAA, and ISO 27001 requirements depending on your context. For sensitive imagery — people, medical, secure sites — privacy, proportionality, and governance are part of the design, not an afterthought, so the system stands up to a compliance review.
Often, yes. If you have a model that's inaccurate, slow, or fails in certain conditions, we assess it and frequently improve it — more representative data, augmentation, a better-suited architecture, or edge optimisation — rather than starting over. Sometimes a fresh build is cheaper; we'll tell you honestly which.
Yes to both. Every engagement includes 90 days of post-launch support — accuracy monitoring, tuning, and adjustments — with retainers beyond that for ongoing monitoring, re-training as conditions change, new visual tasks, and maintenance, because an unmaintained vision model drifts as the world in front of the camera changes. And ownership is complete: the trained models, code, pipelines, annotated datasets, and documentation are yours unconditionally, including custom models trained on your images. We sign NDAs before any discovery conversation and never reuse your data for anyone else.
Discover complementary services that pair with your computer vision — from machine learning and NLP to integration, MLOps, and AI strategy.