15+ Years
Enterprise software delivery since 2009 — a track record built across technology cycles, not just the current AI wave.


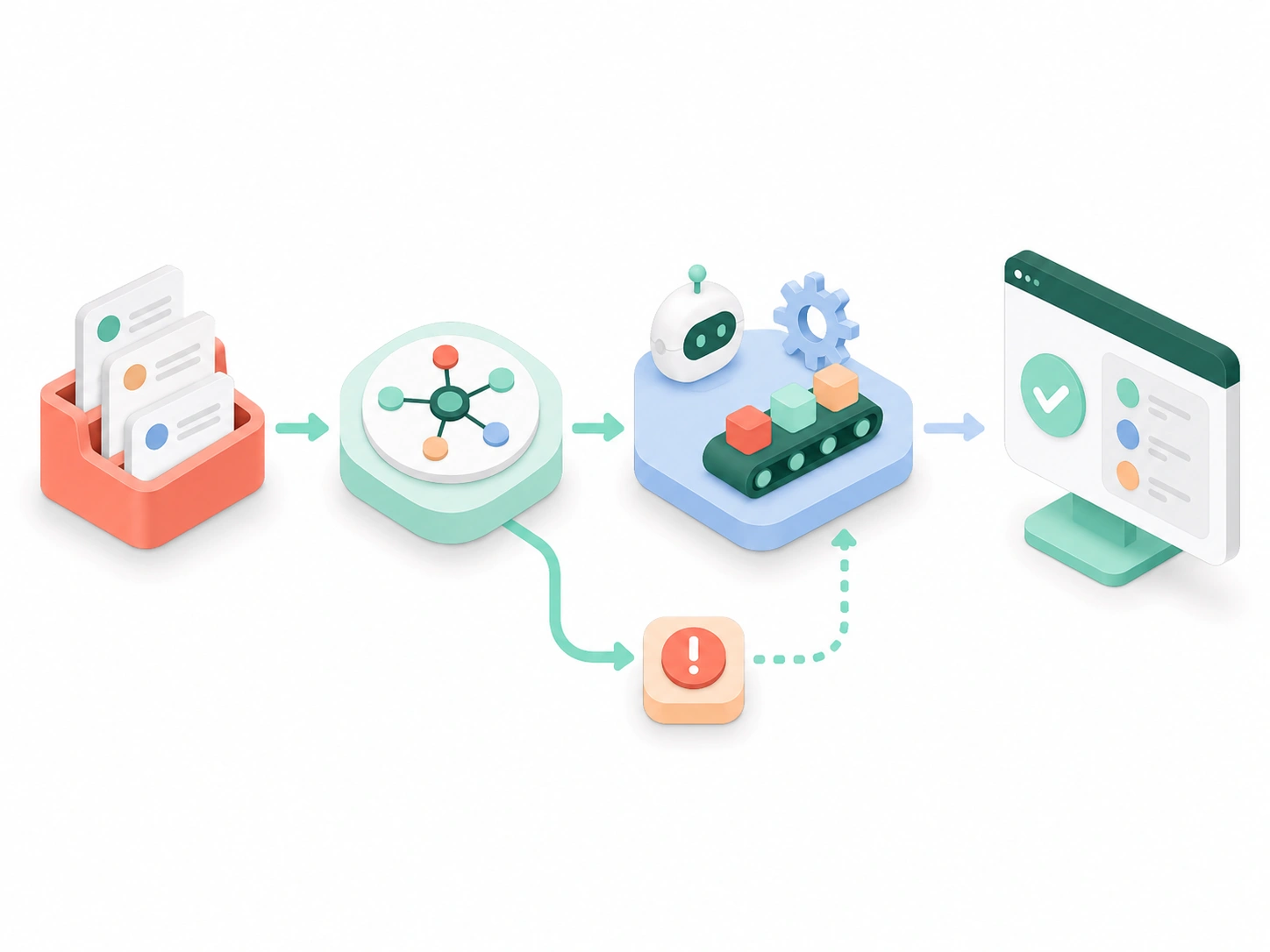
Build AI agents that plan, decide, and act across your enterprise — from single-task automation agents to governed multi-agent systems with human-in-the-loop controls. Built for services firms ready to compete with — and outperform — AI-native entrants. Deployed in production.


A decade of AI engineering experience, validated in numbers

Map your highest-value AI use cases, score ROI potential, and build a sequenced roadmap — before writing a line of code.
Single or multi-agent systems purpose-built for your workflow — proposal generation, knowledge retrieval, compliance checks, resource scheduling, and more.

Connect agents to your existing systems: Salesforce, HubSpot, SharePoint, ServiceNow, ERPs, and document repos — via secure API connectors or MCP.
Agents that search and retrieve from your proprietary knowledge base — past proposals, contracts, project archives — using hybrid vector and keyword retrieval
Production observability: latency tracking, hallucination detection, cost monitoring, action audit trails, and human-in-the-loop escalation gates.

Embedded AI copilots inside your existing tools — Outlook, Teams, SharePoint, CRM — so users get agent-powered assistance without leaving their workflow.
A fixed-scope, fixed-price 6-week proof of concept that proves ROI before you commit to a full build. Success criteria defined upfront. No ambiguous outcomes.
Orchestrate teams of specialized agents using LangGraph, CrewAI, or AutoGen. Each agent has its own role, tool set, and defined authority scope.

Replace brittle rule-based workflows with adaptive agents that plan, act, and self-correct — even when inputs or process conditions change mid-execution.
Give your agent access to legacy systems without full migration — via MCP (Model Context Protocol) or structured API wrappers. No rip-and-replace required.
Agents that autonomously gather, synthesize, and cite from internal archives and external sources — for due diligence, competitive intelligence, and bid research.
Our AI agents are tailored to the specific workflows, data environments, and governance requirements of each industry.
Consulting & Advisory AI-powered proposal automation, knowledge retrieval, bid generation, and resource scheduling for multi-practice consulting firms.
Trusted by Rodic Consultants
SaaS & Digital Platforms. Build intelligent product experiences with AI copilots, automated onboarding workflows, and analytics agents inside your platform.
Engineering & Infrastructure. Use AI agents for project knowledge retrieval, site inspection intelligence, predictive maintenance, and compliance monitoring.
Financial Services. Automate document review, compliance checks, KYC workflows, risk scoring, and client reporting with governed AI agents.
Supply Chain & Logistics. Improve vendor communication, demand forecasting, shipment tracking, and inventory intelligence with autonomous agents.
Healthcare & Research. Enable medical document intelligence, research summarization, patient support workflows, appointment automation, knowledge assistants, and secure data analysis.
CleanTech & Mobility. Support sustainability operations, fleet intelligence, energy monitoring, and compliance workflows with AI agents.
EdTech Platforms. Improve learner support, content operations, student onboarding, and course personalization with AI agents.
Non-Profits & FoundationsAutomate grant research, donor communication, impact reporting, and program coordination with AI agents.








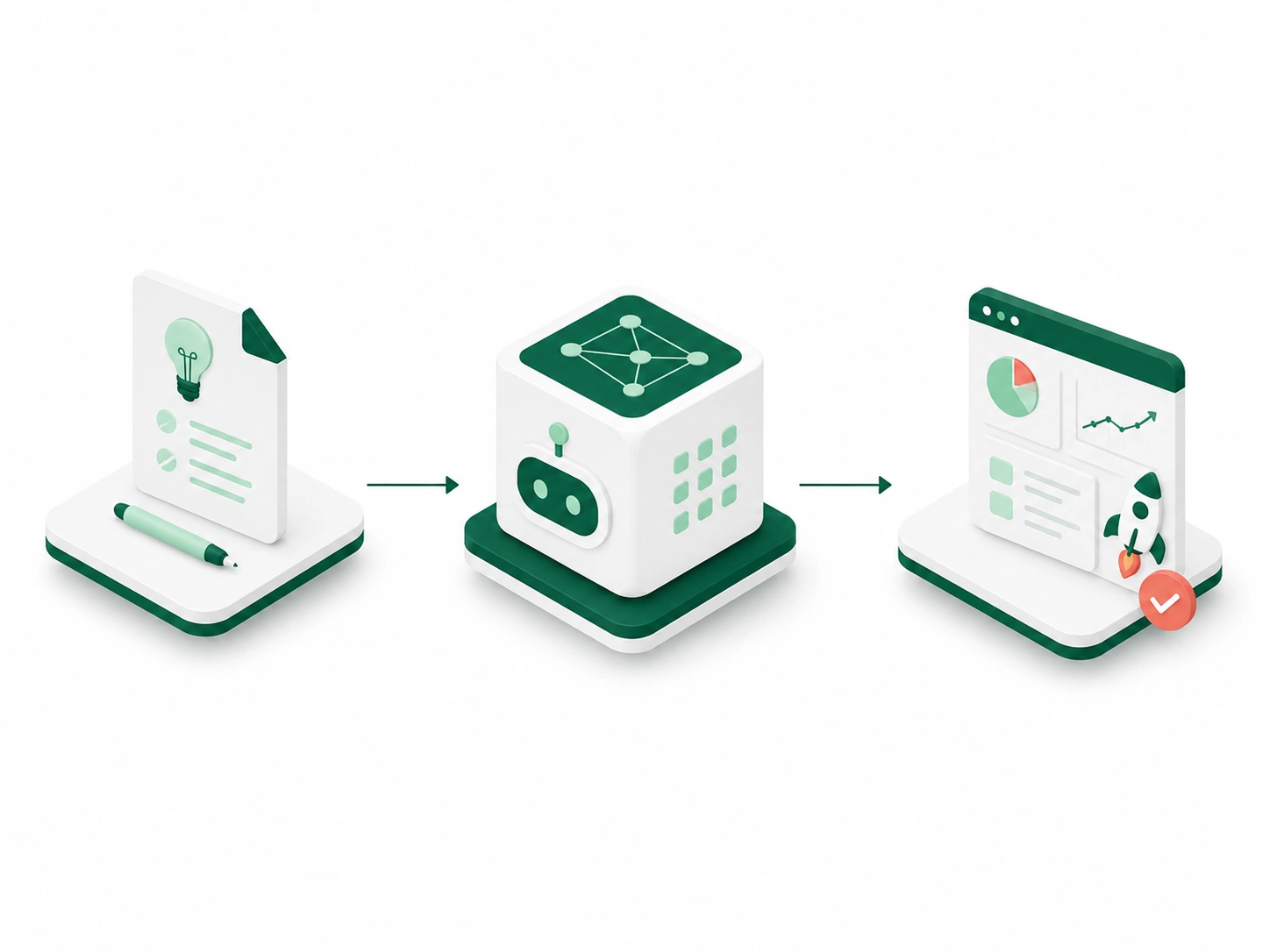
We combine deep AI expertise with enterprise delivery practices to ship production-ready intelligent systems.
Enterprise software delivery since 2009 — a track record built across technology cycles, not just the current AI wave.
Independently certified, annually audited — meets the security baseline enterprise procurement actually checks.

Nine in ten enterprise clients return for follow-on work — the only measure of delivery quality that cannot be faked.

Verified client reviews, independently collected — real feedback from real enterprise engagements.

Certified cloud partnerships with AWS and Microsoft Azure — enterprise infrastructure standards from day one.

DataSense, DocSense, BidSense — proprietary pre-built AI products that go live in weeks, not months of custom build.

IP, data, and strategy protected before the first discovery call ends — not after contracts are signed.

Post-deployment optimisation included in every engagement — we stay accountable until the system is performing.

62% of enterprises are already experimenting with AI agents, per McKinsey. The other 38% are falling behind faster than they think.
The AI agent conversation has moved well past the 'what is this?' stage. The early majority has arrived — and the gap between firms that deployed in 2023–24 and those still evaluating is already visible in margins and win rates.
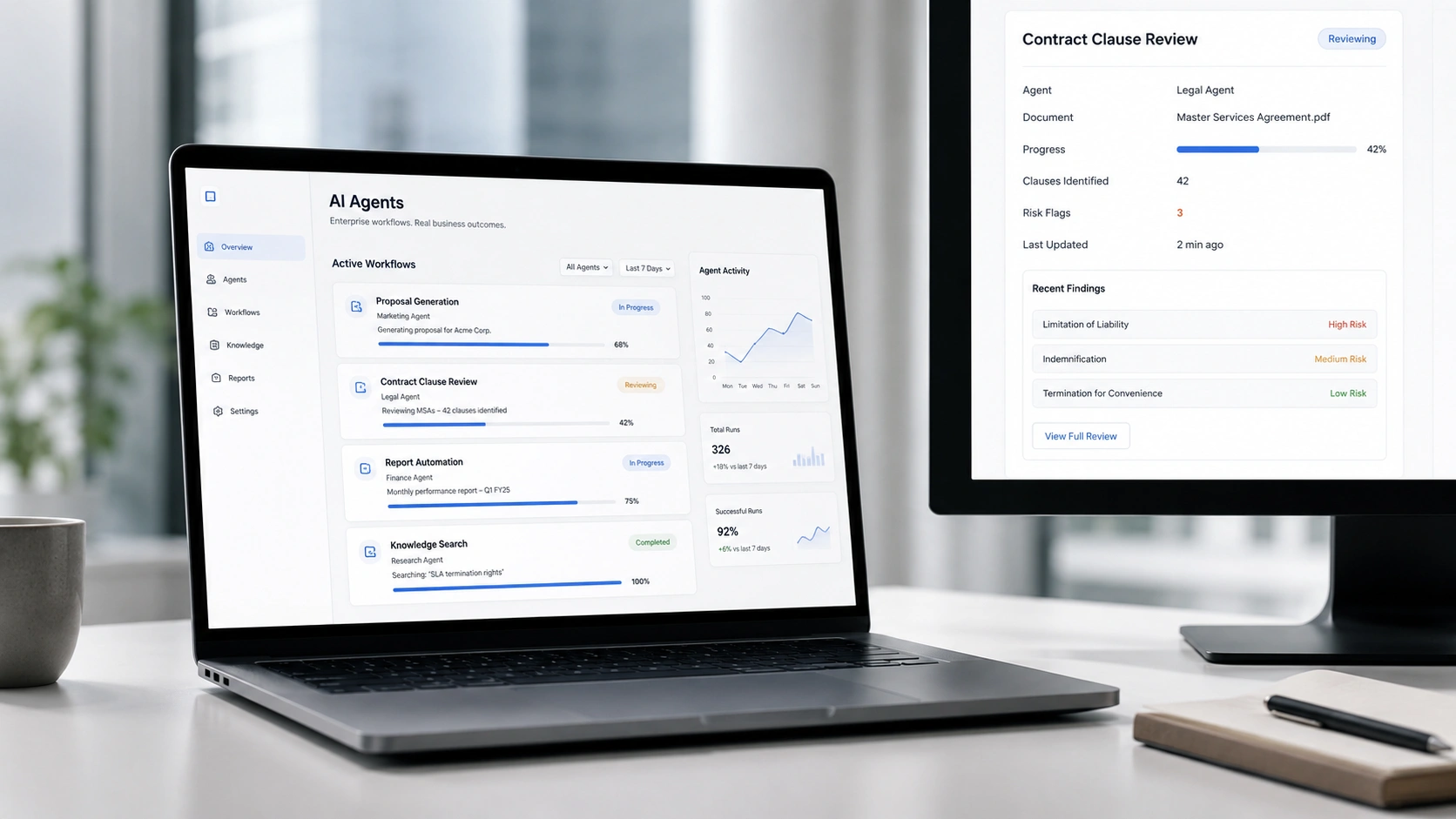
The most common live deployments are not R&D experiments. Proposal and bid agents — ingesting RFPs, pulling from past wins, generating first drafts in under 30 minutes instead of 2–3 days. Contract review agents — flagging non-standard clauses across 50+ page documents in minutes. Client reporting agents — synthesising project data into formatted weekly reports without a team member touching them. Knowledge retrieval agents — answering 'what did we do for a similar client in 2022?' in seconds, not days. These are running today in mid-market consulting firms, Big 4-adjacent practices, and specialist advisory businesses.
Of the AI projects that failed between 2022 and 2024, most shared three failure modes: agents deployed without a proper data layer (outputs were unreliable), no governance design (agents acted outside intended scope), and no production architecture (what worked in the demo broke at scale). The firms that survived those lessons are now building data-first, governance-in, production-ready from day one.
Professional services is the fastest-moving sector. The economics are direct: every agent-assisted deliverable that takes 2 hours instead of 8 frees 6 hours of billable capacity. A firm with 80 consultants running 3 agent-assisted workflows recovers hundreds of hours per week — without adding a single hire. The firms building this infrastructure now are establishing a gap that will be difficult to close in 24 months.
These are not abstract business problems. They are the conversations happening in leadership meetings at services and consulting firms right now.

A mid-size consulting firm with 60 billable staff hits a ceiling: to grow revenue, they need more people. Hiring is slow, expensive, and dilutes average quality. The firms breaking this constraint are running AI agents on high-volume, repeatable work — research synthesis, first-draft deliverables, data gathering — freeing their people for the higher-value work clients pay premium rates for. One management consulting firm reduced per-engagement research time by 74% without changing team size.
In most firms, quality depends on who's on the project. The partner-led engagement is exceptional. The junior-led one is inconsistent. Agents trained on your methodology, past deliverables, and quality standards function like a senior reviewer embedded in every workstream. One professional services firm reported a 40% reduction in internal rework after deploying a methodology agent across delivery teams.
The average tenure at a professional services firm is 3.1 years. Every departure takes project context, client preferences, and hard-won lessons with it. A knowledge agent indexed on your project archive, client notes, and internal documentation means that context survives. One firm recovered over 200 hours of partner time in the first quarter after deploying an internal knowledge agent — time previously spent answering questions that were already answered somewhere.
A new category of services firm is emerging: leaner, faster, and able to offer comparable outputs at significantly lower cost because their delivery is partially agent-powered. Procurement teams at enterprise clients are already comparing proposals from established firms against these leaner competitors. The window to close that gap on your own terms — before your clients notice the difference — is now.
The market for AI agent development is crowded. Most vendors offer variations of the same thing: a pre-built framework, a fast demo, and a handoff. Here is what a genuinely different engagement looks like — and how to tell the difference before you sign anything.

A template vendor shows you an agent demoed a hundred times on clean data with predictable inputs. Ask them what happens when it encounters your CRM schema, your legacy document formats, or a workflow that doesn't fit their standard pattern. A serious partner starts with your data, your systems, your edge cases — before designing anything. They will tell you when your infrastructure isn't ready. Template vendors won't. Question to ask any vendor: 'Show me a deployment where you had to build a custom integration for a legacy system. What broke, and how did you handle it?'
A vendor with a preferred tech stack will recommend that stack regardless of your situation. A strategy-first partner tells you when LangGraph is the right choice and when it isn't — when a simpler rule-based system outperforms an LLM agent for a specific use case, and when RAG adds cost without value. Red flag: any vendor who proposes a full multi-agent system in the first meeting without asking about your data maturity.
An agent shipped and forgotten drifts. Models change. Business rules change. Regulations change. An agent that was 94% accurate at launch can be 71% accurate 8 months later if nobody is monitoring it. Ask every potential partner: what does your LLMOps practice look like? How do you handle model drift? What's the retraining cadence? Silence or vagueness is a significant answer.
The right partner defines success as: cost per proposal reduced from £2,400 to £420. Research time per engagement from 22 hours to 4. Not: latency below 800ms and 96% retrieval accuracy. Both matter — but the first is what you take to a board. Ask every vendor what the business metric for success is on day 90, not just the technical benchmarks.
Readiness is not a binary yes/no. It is a map — and knowing where your gaps are shapes how you scope the first deployment. Here are the four dimensions to assess before writing a brief.

85% of enterprise AI projects that fail do so because of data problems, not technology problems. Four questions to answer honestly: Is the data the agent will rely on accessible via API or structured format — or locked in PDFs, email threads, and shared drives? Is there a single source of truth, or multiple conflicting versions? How recent is the data? Who owns data governance? If the answer to the last question is 'nobody, really' — the first investment is not the agent.
Draw the map before you build the agent. For a typical consulting engagement, a workflow touches: CRM for client data, project management for timelines, document management for deliverables, email for communications, and finance for billing. Each integration point is a potential failure mode. The firms that ship agents fastest are the ones who complete this mapping in week one, not week eight.
Every enterprise agent needs three governance elements before production: a defined authority scope (what it can do, what it must escalate, what it refuses); a human-in-the-loop checkpoint for decisions above a defined consequence threshold; and an audit trail. Build these before you build the agent. It takes two weeks, not two months, and it prevents the kind of incident that sets a programme back by a year.
A readiness gap is not a reason to pause. It is a reason to scope carefully. The right starting point: a PoC targeting one workflow with clean data, one team with clear buy-in, one measurable outcome defined in advance. Most successful enterprise agent programmes started with something that took 6 weeks to ship and saved 15 hours per week. That proof of value is what unlocks the budget and internal alignment for everything that follows.
These are outcomes documented in live enterprise deployments — not projections.

A one-time software efficiency gain is fixed. An agent improves with every interaction — better retrieval, better calibration, more accurate outputs over time. One financial services consulting firm measured a 3.2x output increase per analyst in the first year of agent-assisted work. By year two, the same agents were delivering 5.1x — not because the technology changed, but because the agent had indexed more of the firm's knowledge. (Source: VOCSO client engagement, 2024.)
A partner making a competitive entry recommendation used to need a week of research. With a market intelligence agent pulling from structured databases, internal project archives, and live market signals, the briefing is ready in 90 minutes. The partner spends their time on the insight, not the retrieval. This is changing what is possible in client conversations — and in competitive pitches.
Human errors in professional services follow patterns: missed contract clauses, inconsistent data formatting, overlooked compliance obligations. Agents operating on structured validation logic catch these systematically. One legal services firm reported a drop in contract review errors from 11% to under 1.5% after deploying a clause-checking agent — without adding a single reviewer. (Industry benchmark, IBM Institute for Business Value.)
Enterprise procurement teams are now asking vendors direct questions about AI governance: What do your agents do with client data? Can you show an audit trail? What is your human oversight model? Firms with auditable, documented, explainable agent workflows answer these confidently. Two firms in the UK professional services market cited a documented AI governance framework as an explicit reason for awarding contracts in 2024. It is no longer just risk management — it is competitive differentiation.
Weeks 1–2
We define the right agent use cases, workflows, data access, and control boundaries before development begins.
Weeks 3–5
We build the core agent architecture, including model selection, tool connectors, memory, and orchestration logic.
Weeks 5–8
We connect the agent with your business systems, knowledge sources, APIs, and secure enterprise data flows.
Weeks 8–9
We implement monitoring, audit trails, escalation controls, and safety rules to keep agent behavior reliable and compliant.
Weeks 9–12
We launch a controlled pilot, gather real-user feedback, refine the system, and move it into production with support.
Book a free 30-minute discovery call with a senior AI engineer — no slide deck, just questions about your workflows, your data, and your goals.
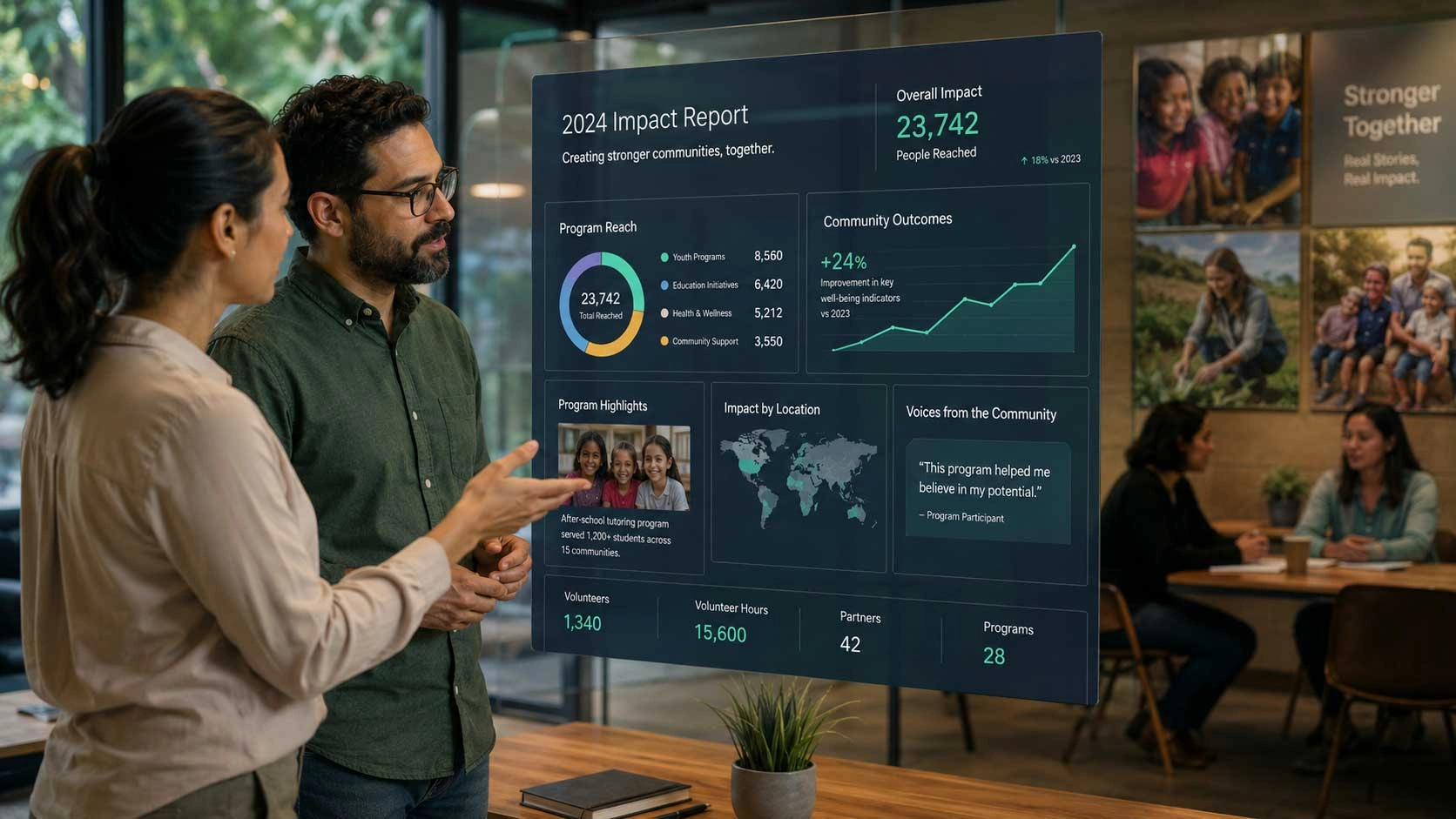
Enabled users to retrieve operational, financial, and project insights through natural language queries, transforming complex data analysis into instant, self-service intelligence.
See case studyWe stay at the cutting edge of agentic AI, using capable models, orchestration frameworks, vector databases, and deployment infrastructure — selecting the right combination for your architecture, use case, and security requirements.
State-of-the-art models for reasoning, generation, and tool use.
Coordinate agents, tools, and workflows with reliability and control.
High-performance vector databases for semantic search and retrieval.
Store, recall, and manage agent memory and long-term state.
Modern languages and runtimes for building AI applications.
Connect to tools, APIs, and external systems seamlessly.
Monitor, trace, and evaluate AI systems in production.
Enterprise-grade cloud services and infrastructure foundations.
Enterprises trust VOCSO for AI consulting services built to scale securely and meet regulatory standards. We design enterprise-grade AI systems that balance innovation with compliance across AWS, Azure, and Google Cloud.

General Data Protection Regulation

Information Security Management Systems

System and Organization Controls
For AI applications in healthcare

Responsible AI principles and implementation

AI Risk Management

Principles and implementations
India’s personal data protection framework

Auditability frameworks

Standards and evaluation practices
Validate an AI agent use case with a low-risk, fixed-scope engagement designed to prove value, feasibility, and ROI before committing to a full build.
 Dedicated AI Team
Dedicated AI TeamA cross-functional AI agent team embedded into your environment — working within your processes, security requirements, and communication tools.
End-to-end delivery of a defined AI agent capability with fixed scope, timeline, and commercial terms. Full knowledge transfer and documentation included.
Let's discuss the right engagement model for your project?
Book a callFirst-hand experiences from firms that deployed AI agents, scaled intelligently, and achieved measurable results.
View all client testimonials“Vocso team has really creative folks and is very co-operative to implement client project expectations. MicroSave Consulting had great experience working with Anju and Prem.”

“Working with Deepak and his team at Vocso is always a pleasure. They employ talented staff and deliver professional quality work every time.”

“We love how our website turned out! Thank you so much VOCSO Digital Agency for all your hard work and dedication.”

“VOCSO SEO & SEM services helped me find new customers in a small budget. Their advanced SEO strategies made us visible to everyone.”

“Vocso team has really creative folks and is very co-operative to implement client project expectations. MicroSave Consulting had great experience working with Anju and Prem.”
“Working with Deepak and his team at Vocso is always a pleasure. They employ talented staff and deliver professional quality work every time.”
“We love how our website turned out! Thank you so much VOCSO Digital Agency for all your hard work and dedication.”
“VOCSO SEO & SEM services helped me find new customers in a small budget. Their advanced SEO strategies made us visible to everyone.”
Most agent demos fail in production because they treat memory as an afterthought — and the agent forgets everything the moment a session ends.
An AI agent without properly designed memory is not an agent — it's a stateless chatbot with extra steps. Memory is what makes agents capable of handling multi-txurn, multi-session, multi-user workflows in enterprise environments.
Short-term memory — In-context working memory for the current session — managed via the orchestration framework's state object, not the LLM's context window alone.
Long-term memory — Persistent storage (PostgreSQL + vector index) for cross-session recall — project context, user preferences, prior decisions, and past outputs.
Episodic memory — A log of what the agent did, in what order, and with what outcomes — essential for audit trails and human review of agent decisions.
Forgetting strategy — Memory must have a defined eviction policy — not everything should persist indefinitely. We design TTL and relevance-based pruning into every memory layer.
At VOCSO, memory architecture is designed in the Discovery phase — because getting it wrong means rebuilding the agent, not tweaking a prompt.
An agent that can call tools unreliably is more dangerous than no agent at all — it creates invisible errors that compound across multi-step workflows.
Tool use is where most enterprise AI agents break down in production. Every tool call is a potential failure point: bad parameters, timeout, unexpected response format, permission denied. The agent needs to handle all of these gracefully — not crash, not silently hallucinate a response.
Tool schema validation — Every tool call is validated against a strict schema before execution — the agent cannot pass malformed parameters to a live system.
Retry logic with backoff — Transient failures (API timeouts, rate limits) are handled with exponential backoff and a maximum retry count — not infinite loops.
Error state handling — When a tool fails, the agent logs the failure state with full context, stops the affected workflow branch, and creates a human handoff task.
Audit logging — Every tool invocation — parameters, response, latency, outcome — is logged to a persistent audit trail. Required for compliance-sensitive workflows.
VOCSO tests every tool connector against real failure scenarios before promotion to production — API down, malformed response, rate limit, permission denied, and partial response.
The coordination pattern you choose determines whether your multi-agent system is debuggable — or a black box that fails silently under load.
Multi-agent systems introduce a coordination problem that doesn't exist in single-agent designs. Who decides which agent runs next? How do agents share state? What happens when two agents conflict? Getting this wrong produces systems that are impressive in demos and unreliable in production.
Supervisor pattern — A central supervisor agent orchestrates specialist agents, assigns tasks, resolves conflicts, and enforces completion criteria. Best for workflows with clear sequencing.
Peer-to-peer pattern — Agents communicate directly, passing messages and results between themselves. Best for parallel workloads where agents operate independently.
Human-in-the-loop gate — Either pattern benefits from a defined set of conditions under which the orchestrator pauses and requests human input before continuing.
State management — Shared state is the hardest engineering problem in multi-agent systems. We use LangGraph's typed state graph to make state transitions explicit and testable.
At VOCSO, the coordination pattern is defined at the agent design phase and documented in the agent design spec — not figured out during debugging.
Shipping an agent to production without a defined evaluation framework is not a risk you take — it's a mistake you make.
A language model that sounds confident is not necessarily correct. An agent that completes a task in a demo is not necessarily reliable under the edge cases, adversarial inputs, and system failures that production environments generate every day. Evaluation is how you find those gaps before your users do.
Task completion rate — Does the agent complete the target workflow end-to-end, without errors, on a representative sample of real inputs? Measured against a labelled test set.
Tool call accuracy — Are tool calls made with correct parameters? Are malformed calls caught before execution? Measured per tool, per workflow step.
Retrieval quality (for RAG agents) — Is the retrieved context relevant? Are citations accurate? Measured using precision@k and MRR against a test query set.
Failure mode coverage — Has the agent been tested against all defined failure scenarios — bad input, tool unavailable, ambiguous instruction, missing data? Each failure mode has a pass/fail criterion.
No VOCSO agent ships to production without passing its evaluation benchmark. We define success criteria at the start of every project — not after the first deployment failure.
An AI agent without governance isn't an enterprise tool — it's a liability.
Governance for AI agents is not a compliance checkbox. It is the engineering discipline that determines what the agent is allowed to do autonomously, what requires human approval, and what can never happen at all — and it needs to be enforced at the orchestration layer, not just described in the system prompt.
Authority scope definition — Every agent has a precisely defined set of permitted actions. Write permissions, API scopes, and data access are granted by action — not by session.
Mandatory escalation conditions — Specific conditions — output uncertainty above threshold, high-stakes action, ambiguous instruction — trigger a mandatory human review gate before execution continues.
Audit trail — Every agent action — tool call, decision, escalation, output — is logged to an immutable audit trail with timestamps, parameters, and outcomes. Required for regulated industries.
Prompt injection defences — We test every agent against prompt injection — user inputs designed to override the agent's instructions. Defence is at the orchestration layer, not just prompt wording.
VOCSO governance design is independent of the LLM. We enforce authority scope through the orchestration framework — so it cannot be overridden by a crafted user message, no matter how clever.
You delivered exactly what you said you would in exactly the budget and in exactly the timeline.





Most services firms start with one high-value workflow — typically proposal generation, knowledge retrieval, or compliance monitoring. We help you scope, design, and prove it in 6 weeks. No open-ended contracts. No ambiguous scope.
deepak@vocso.com — no forms, no funnels.
We build a comprehensive range of AI agents: task agents for single-step automation, research and retrieval agents for knowledge work, proposal and bid agents for consulting firms, process orchestration agents for multi-step workflows, data and analytics agents for reporting, and compliance monitoring agents for regulated environments. We also build the underlying infrastructure: RAG layers, memory architectures, tool connectors, and governance frameworks.
LangGraph is our default for enterprise consulting workflows because it gives precise control over agent state, transitions, and human-in-the-loop gates — it makes the agent's decision logic explicit and testable, which matters in compliance-sensitive or client-facing deployments. CrewAI suits multi-agent role-based systems where agents have defined personas and collaborate toward a shared goal — well-suited for research pipelines and document synthesis tasks. AutoGen works for dynamic, conversational multi-agent patterns. In a discovery call, we'll ask about your workflow specifics and recommend the right one — we're not tied to any of them.
AI agent development costs vary based on complexity, integration requirements, and governance depth. A single-task agent with limited system access typically runs $15,000–$35,000. A multi-agent system with enterprise integrations, RAG layers, and full governance runs $40,000–$120,000+. We offer a fixed-price POC (typically $12,000–$20,000) to validate your use case before committing to a full build. Every engagement starts with a free 30-minute discovery call to scope requirements and provide a realistic estimate.
A production-ready agent for a consulting firm workflow typically takes 10–14 weeks: 2 weeks for discovery and design, 5–6 weeks for build and integration, 2 weeks for governance hardening and pilot, then production deployment. A scoped proof of concept runs in 6 weeks. The largest variable is system accessibility — if your CRM and document repo have well-documented APIs, integration is fast. Legacy systems without API layers add 2–3 weeks for connector development.
Yes — and security is where most enterprise agent builds fail when not designed correctly from the start. We implement Zero Trust architecture for all agent-to-system connections: identity-first access, least privilege per action, no persistent credentials stored in the agent runtime, and a full audit trail of every API call the agent makes. The agent only accesses what it needs, when it needs it, with a logged reason. This architecture satisfies most enterprise vendor security questionnaires and is compatible with ISO 27001 controls.
We define an authority scope for every agent — the specific tools it can use, the systems it can write to, and the conditions under which it must stop and request human approval. This is enforced at the orchestration layer (not just in the LLM prompt), so it cannot be overridden by a crafted input. All actions are logged with full trace context. High-stakes actions — sending a client email, updating a contract record, triggering a payment — always require explicit human confirmation before execution.
Yes — this is one of our most common deployments for consulting firms. The agent receives an RFP or project brief, extracts key requirements, searches your past proposal archive via DocSense for relevant precedents, drafts a structured response against your standard template, and flags sections where information is missing. A human reviews and edits the draft before submission — the agent never sends anything autonomously. Typical time saved: 3–5 hours per proposal.
We design every agent with explicit failure modes. If the agent cannot complete a step — bad data, ambiguous instruction, missing tool access, unexpected system response — it logs the failure state, stops execution, and creates a human handoff task with full context: what it tried, what failed, and what it needs to proceed. It never silently continues with incorrect data or guesses past an error. Post-launch, our monitoring dashboard surfaces failure rates by agent action type so you can continuously improve data quality and the agent's authority scope.
We are framework-agnostic and select based on the architecture requirements of your workflow. LangGraph is our default for complex, stateful workflows requiring precise control over agent transitions and human-in-the-loop gates. CrewAI suits multi-agent role-based systems where agents have defined personas and collaborate on a shared goal. AutoGen works well for dynamic, conversational multi-agent patterns. For most consulting firm workflows, LangGraph is our preferred choice because it makes agent state and transitions explicit and testable.
Yes — copilot-style agents embedded inside your existing tools consistently get the highest adoption rates because users don't need to change their workflow. We build AI agents accessible via Microsoft Teams bot, Outlook add-in, SharePoint web part, and custom chat interfaces embedded in your existing web applications. The agent connects to the same backend as a standalone system — the interface is just surfaced where your team already works.
Integration with existing systems is one of our core strengths. Whether your data lives in SharePoint, Confluence, Salesforce, SAP, Oracle, or a custom ERP — we build connectors and data pipelines that make it accessible to your agents. For legacy systems without documented APIs, we develop structured API wrappers or use MCP (Model Context Protocol) to expose system capabilities to the agent without a full integration build.
AI hallucinations — where a model generates plausible-sounding but incorrect outputs — are one of the primary risks in production agent systems. We address this at multiple layers: RAG grounding (agent retrieves source documents and bases its output on them, with citations), output validation (structured outputs are validated against a schema before use), confidence thresholds (outputs below a confidence score trigger a human review gate), and hallucination-specific test cases in our evaluation framework. No VOCSO agent ships without a defined hallucination rate benchmark.
We are model-agnostic by design. We evaluate GPT-4o, Claude 3.5/4, Gemini Pro, Llama 3, and Mistral against your specific use case requirements — latency, accuracy on your domain, cost per call, and data residency constraints. For some applications a hosted API model gives the best accuracy. For others, a self-hosted open-source model is required because your data cannot leave your infrastructure. We make this decision at the architecture phase and document the selection rationale.
This is one of the most common conversations we have — and the answer is almost always: start with a PoC that proves value on a workflow your sceptics already agree is painful. Don't ask for belief upfront; ask for a 6-week test on one specific workflow. We've seen the most resistant delivery teams become the strongest internal advocates after a proposal agent saved them 4 hours on a single bid. The format that works: define the success metric before the PoC starts, involve one sceptic in the testing process, and present results in business terms — hours saved, error rate reduction, turnaround time — not technical accuracy scores.
Most consulting firm engagements start with a fixed-price AI Discovery Sprint — a two-week engagement where we interview stakeholders, audit your data and systems, map your three highest-value agent use cases, and produce a concrete implementation brief with estimated effort, timelines, and ROI projections. You own the brief outright. From there, the most common first agent build is either a proposal/bid agent (DocSense-powered) or a project knowledge retrieval agent — both deliverable in 6–8 weeks with measurable results.
A VOCSO AI agent proof of concept runs 4–6 weeks with a fixed scope and fixed budget, typically between $12,000 and $20,000 depending on integration complexity. We define measurable success criteria before any work begins — so there are no surprises about what 'done' looks like. The POC covers: a working agent on your real data, integration with at least one live system, a governance framework, and an executive-ready ROI assessment to support your internal business case.
All intellectual property is fully and unconditionally owned by you. We execute NDAs before any discovery conversation — not just before development begins. Your data, your models, your outputs, and all code we produce are yours. We do not retain any client data after a project concludes. For firms with stricter requirements — financial services, legal, defence-adjacent consulting — we operate in customer-managed cloud environments where we never have direct access to production data at all.
Yes — we connect AI agents to Salesforce, HubSpot, SAP, Oracle, Microsoft Dynamics, Jira, Monday.com, Asana, ServiceNow, and most other enterprise platforms via their APIs. For systems without documented APIs, we build structured wrappers. AI that works inside the tools your teams already use gets adopted. AI that requires a new interface to exist alongside existing tools does not.
The two highest-ROI entry points are the knowledge retrieval agent (DocSense) and the proposal / bid agent (BidSense from the VocsoAI suite). DocSense makes your entire project archive searchable via natural language — deployed in 4–6 weeks. BidSense reads an incoming RFP, retrieves relevant past proposals, and drafts a structured response — saving 3–5 hours per bid. Both are pre-built capabilities with your data layered on top — significantly faster to deploy than custom-built agents from scratch.
Yes — AI agents require ongoing attention to maintain their effectiveness, and we offer comprehensive post-launch support. Our standard engagement includes 90 days of included support after production launch: monitoring, incident response, model performance review, and minor scope adjustments. Beyond 90 days, we offer support retainers covering model drift monitoring, periodic re-evaluation against new test data, feature additions, and integration maintenance as your underlying systems change.
Absolutely — and we strongly recommend a phased approach for most AI agent initiatives. Phase one is typically a single high-value agent (knowledge retrieval or proposal automation). Phase two adds additional agents and integrations. Phase three introduces multi-agent orchestration and broader workflow coverage. Phased delivery reduces risk, builds internal confidence, and gives you proof points to justify further investment to leadership.
Discover complementary services that enhance performance, improve user experience, and help your business build scalable digital solutions efficiently.