15+ Years
Enterprise software delivery since 2009 — a track record built across technology cycles, not just the current AI wave.


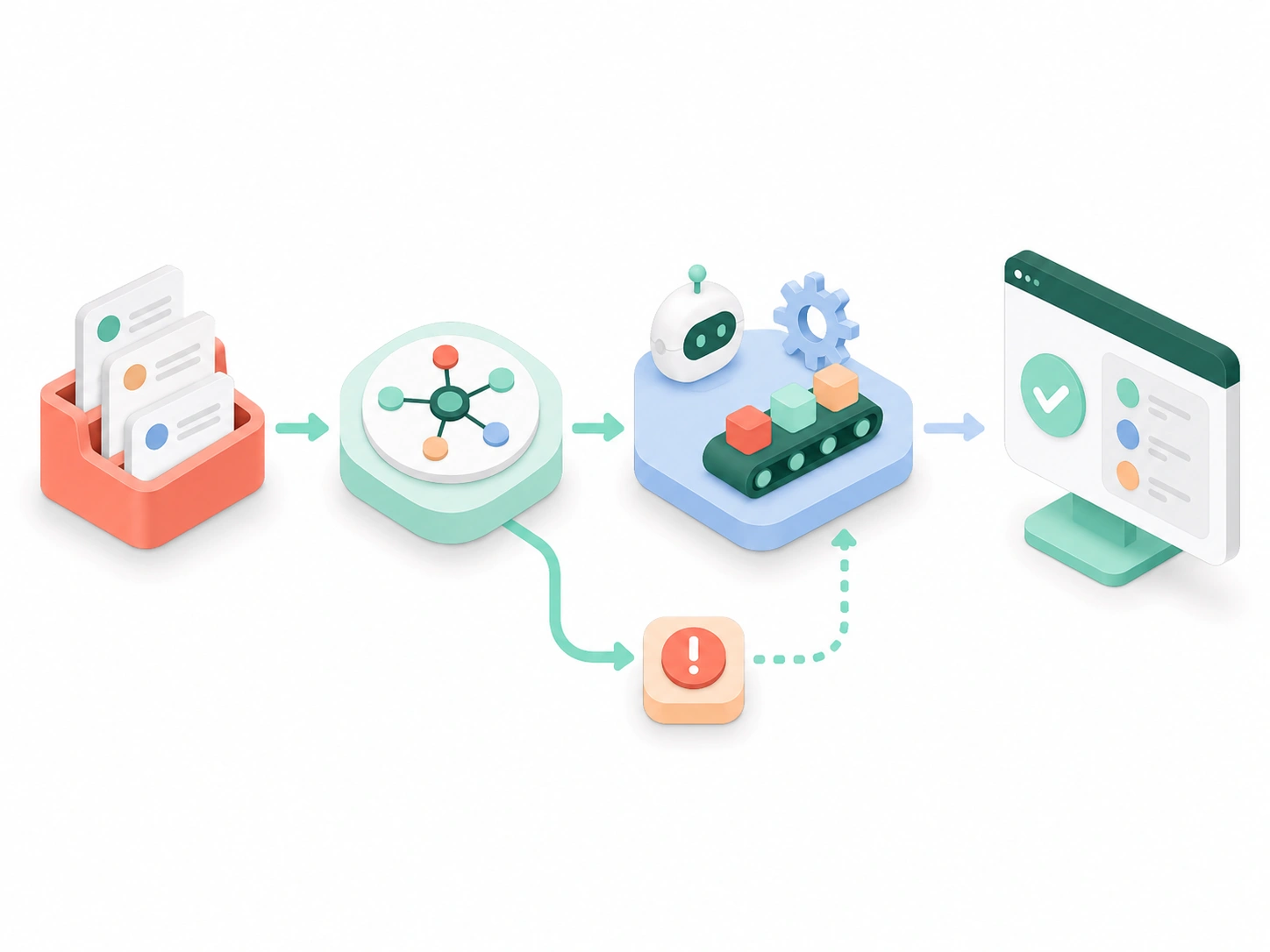
An LLM demo takes a weekend; an LLM product that survives real users takes everything after it. We build that 'everything after' — copilots, assistants, document intelligence, and custom GenAI products engineered with evaluation, guardrails, retrieval, and cost control baked in, not bolted on. Model-agnostic, measured against your own test set, and handed over for your team to own.


A decade of AI engineering experience, validated in numbers

Eval suites that measure accuracy, hallucination, and regressions on every change — plus input/output guardrails, content filtering, and confidence thresholds that stop bad outputs reaching users.
Prompt design treated as engineering: versioned, tested, and benchmarked. Structured outputs, few-shot patterns, and prompt chains tuned for reliability and token efficiency.
Turn unstructured documents into structured data — contracts, invoices, reports, and forms — with LLM extraction, classification, and summarisation validated against a schema before use.
Ground your LLM in your own data with retrieval-augmented generation — hybrid search, re-ranking, and cited answers — so outputs are accurate and verifiable, not hallucinated.
When prompting isn't enough, adapt the model to your domain — instruction tuning, LoRA/QLoRA, and embedding fine-tuning — for higher accuracy at lower inference cost.

Custom generative-AI products — content generation, copilots, and GenAI features — built on the model and architecture choices your LLM app needs.

When your app needs to take actions, not just answer — governed multi-step agents with tools, memory, and human-in-the-loop controls.
Wire the LLM app into the systems you already run — CRM, ERP, and data warehouses — via secure connectors, APIs, and tool calling.
Secure, governed conversational AI with RBAC, audit logs, and compliance built in — for customer- or employee-facing assistants, not a generic widget.
Let users query your data warehouse in plain language and get governed, trustworthy answers — natural-language analytics with no SQL required.
Classification, extraction, sentiment, and entity recognition — classical and LLM-based NLP for the tasks where a full LLM app would be overkill.
Our LLM applications are tailored to the specific workflows, data environments, and governance requirements of each industry.
Consulting & Advisory LLM apps for proposal drafting, knowledge search, and client reporting across multi-practice consulting firms.
Trusted by Rodic Consultants
SaaS & Digital Platforms. Ship LLM features inside your product — copilots, in-app assistants, and natural-language search that lift activation and retention.
Engineering & Infrastructure. LLM apps for technical document search, spec extraction, and report generation across large project archives.
Financial Services. Governed LLM apps for document review, KYC, and client reporting — with guardrails, citations, and audit trails built in.
Supply Chain & Logistics. LLM apps that read documents, answer operational questions, and summarise across vendor and shipment data.
Healthcare & Research. HIPAA-aware LLM apps for medical document intelligence, research summarisation, and clinical Q&A — with strict data controls and citations built into every response.
CleanTech & Mobility. LLM apps for sustainability reporting, technical Q&A, and document automation across energy and fleet operations.
EdTech Platforms. LLM apps for tutoring, content generation, and learner support — grounded in your curriculum, not the open web.
Non-Profits & Foundations LLM apps for grant drafting, donor communication, and report generation that stretch limited budgets.








We combine deep LLM engineering with enterprise delivery practices to ship language-model applications that are accurate, governed, and built to scale.
Enterprise software delivery since 2009 — a track record built across technology cycles, not just the current AI wave.
Independently certified, annually audited — meets the security baseline enterprise procurement actually checks.

Nine in ten enterprise clients return for follow-on work — the only measure of delivery quality that cannot be faked.

Verified client reviews, independently collected — real feedback from real enterprise engagements.

Certified cloud partnerships with AWS and Microsoft Azure — enterprise infrastructure standards from day one.

DataSense, DocSense, BidSense — proprietary pre-built AI products that go live in weeks, not months of custom build.

IP, data, and strategy protected before the first discovery call ends — not after contracts are signed.

Post-deployment optimisation included in every engagement — we stay accountable until the system is performing.

Standing up an LLM demo is a weekend's work — that's the trap. The distance between something that wows in a meeting and something that holds up in front of real users is where most LLM projects quietly die. Here are the truths that separate the two.
Anyone can wire an LLM to an API and show something impressive on tidy inputs. The unglamorous 90% — making it reliable on real data, at real scale, within budget — is the part nobody demos and every project underestimates.

A prototype runs on a handful of clean inputs and a friendly path, so it looks finished when it's barely started. Then it meets a scanned PDF, an ambiguous question, a user who phrases things sideways — and the cracks show. The impressive demo isn't evidence the app works; it's evidence it works once, on inputs you chose. That's a very different claim from 'it works for your users.'
Shipping means handling messy real data, edge cases, concurrent load, latency budgets, a cost ceiling, and the day a provider changes the model under you. None of that shows up in a demo, and none of it is solved by a better prompt. It's solved by evaluation, guardrails, retrieval engineering, and cost design — the work that turns a clever toy into something you can put your name on.
The apps that reach production were engineered with evals, guardrails, and cost control in week one — not bolted on after a demo impressed someone. We start where most vendors stop, because the demo was never the hard part; keeping it reliable in front of real users is.
The single biggest divide between LLM apps that ship and ones that stall is whether the team can answer 'did that change make it better or worse?' Without evaluation, every release is a guess.

Teams that ship on gut feel discover the failures in production, in front of customers, where they're most expensive. An LLM that sounds confident while being wrong is the worst kind of bug — invisible until someone trusts it. The fix isn't more eyeballing; it's a test set that tells you, objectively, how often the app is right.
Before we tune a prompt or pick a model, we build a labelled evaluation set that defines what 'good' means for your use case and scores every change against it. It's the least glamorous artifact in the project and the most valuable — it's what lets you improve the app deliberately instead of poking at prompts and hoping.
An app that was accurate at launch can degrade the day a provider ships a new model version — and without evals you won't notice until users do. Continuous evaluation catches those regressions before release, so a model change becomes a checked upgrade rather than a silent outage of quality.
Once quality is measured, it stops being a mystery and becomes an engineering target. You can see exactly where the app fails, tie each gain to a specific retrieval or prompt change, and report progress in figures rather than adjectives — which is also what lets you defend the project to whoever funds it.
Teams agonise over which model to use, but the model is the easy, swappable part. The retrieval, the data quality, the orchestration, the guardrails — that's the actual product, and it's where the engineering lives.

For any app grounded in your content, the answer is only as good as what retrieval feeds the model — garbage in, confident garbage out. Most 'the LLM is wrong' complaints are really retrieval problems in disguise. We put as much engineering into how the right context gets found as into the prompt that uses it, because that's where accuracy is actually won.
The model is available to everyone; your proprietary content, examples, and feedback are not. That's the real moat. A good LLM app is built to turn your data into reliable answers — which is why two firms using the same model can ship wildly different products, and why the data work is worth more than the prompt cleverness.
We build so the model is a swappable part behind a clean interface, evaluated against your test set rather than chosen by reputation. When a better or cheaper model lands — and one always does — you switch with a measured comparison, not a rebuild. Betting the whole architecture on one provider is a risk we design out from the start.
A vendor who only knows prompting hits a wall the moment prompting isn't enough. Real LLM engineering knows when to add retrieval, when to fine-tune, when a smaller model wins, and when the honest answer is that an LLM is the wrong tool entirely. If every problem gets solved with a longer prompt, that's the ceiling of what you'll get.
Nobody has 'fixed' hallucination, and a vendor who promises they have is selling you something. The professional move is to engineer the system so a confident wrong answer can't reach a user unchecked — and so you'd know if it did.

The most effective defence is to stop the model from improvising in the first place: answer from your retrieved sources, attach citations a user can check, and validate structured outputs against a schema before anything downstream trusts them. A grounded, cited answer is one a reviewer can verify in seconds — which is what turns 'plausible' into 'trustworthy'.
Not every response should ship automatically. Where confidence is low or the stakes are high, the system should hold the answer for human review rather than push it to a customer. Deciding which paths are autonomous and which need a person is a design choice we make deliberately, not a setting we leave to chance.
If users can type into your app, some of them will try to jailbreak it or smuggle in instructions. We test against prompt injection and design the guardrails to hold at the system level, not just in the wording of a prompt — because 'we asked it nicely not to' is not a security control.
Perfect is not on the menu; bounded and measured is. We agree what error rate the use case can tolerate, build the evals to track it, and monitor it in production — so the question stops being 'does it ever hallucinate?' and becomes 'is it within the limit we agreed, and would we know if it drifted?'
An app that costs cents per call in the prototype can cost a fortune at production volume. Cost isn't something you optimise later — it's baked into the architecture you choose on day one.

Most requests don't need your most powerful model. Routing the routine ones to a smaller, cheaper model and reserving the expensive model for the genuinely hard cases can cut inference spend dramatically without users noticing a difference. Treating every call as if it needs the flagship model is the most common reason an LLM bill spirals.
A surprising share of production traffic is near-identical questions answered over and over. Caching answers and reusing retrieved context turns repeated work into near-zero-cost responses — and makes the app faster at the same time. It's unglamorous engineering that quietly pays for itself within weeks.
Reaching for the largest model 'to be safe' is how budgets and latency both blow out. The right default is the smallest model that passes your evals for the task — which you can only know if you measured. Often a mid-tier or fine-tuned smaller model matches the flagship on your specific use case at a fraction of the cost.
The fastest way to get an LLM product cancelled is an unpredictable bill that scales faster than its value. We design unit economics in from the start and watch cost-per-request like any other production metric — so the app stays viable as it grows instead of becoming the thing finance quietly switches off.
A clever prompt can be copied in an afternoon. What a competitor can't copy is your proprietary data, your evaluation harness, and the dozens of iterations that tuned the app to your reality.

If your entire advantage is a system prompt, you don't have an advantage — you have something a competitor reproduces the moment they see your output. The defensible value lives in everything around the prompt: the data you ground on, the retrieval you tuned, the failure modes you've already fixed. That's the part that took real work and can't be screenshotted.
Every correction, every labelled example, every logged failure makes the next version better — and that loop is unique to you. An app wired to learn from its own production data pulls steadily ahead of a generic tool, because it's improving on a problem only your business sees. The moat isn't built on launch day; it's built every week after.
A well-engineered first LLM app leaves you with reusable evals, retrieval, guardrails, and patterns — so the second and third ship far faster than the first. Teams that build this way compound; teams that treat each app as a throwaway experiment start from zero every time. We build the first one to be the foundation, not a one-off.
We hand over the code, the evals, the documentation, and the know-how, so your team can run and extend the app without us. The aim is to leave you owning a capability and the data advantage underneath it — not dependent on a vendor for every change. Your moat shouldn't live on someone else's laptop.
Weeks 1–2
We define the right use cases, success metrics, and data sources — and decide where an LLM genuinely fits — before any build begins.
Weeks 3–5
We select and benchmark models, design prompts, and stand up retrieval or fine-tuning — the core that determines output quality.
Weeks 5–8
We build the application around the model and connect it to your systems, data, and interfaces.
Weeks 8–9
We benchmark accuracy against your test set, add safety guardrails, and tune for cost and latency before launch.
Weeks 9–12
We launch a controlled pilot, iterate on eval results, and move the app into production with monitoring and support.
Book a free 30-minute discovery call with a senior AI engineer — no slide deck, just questions about your use case, your data, and your goals.
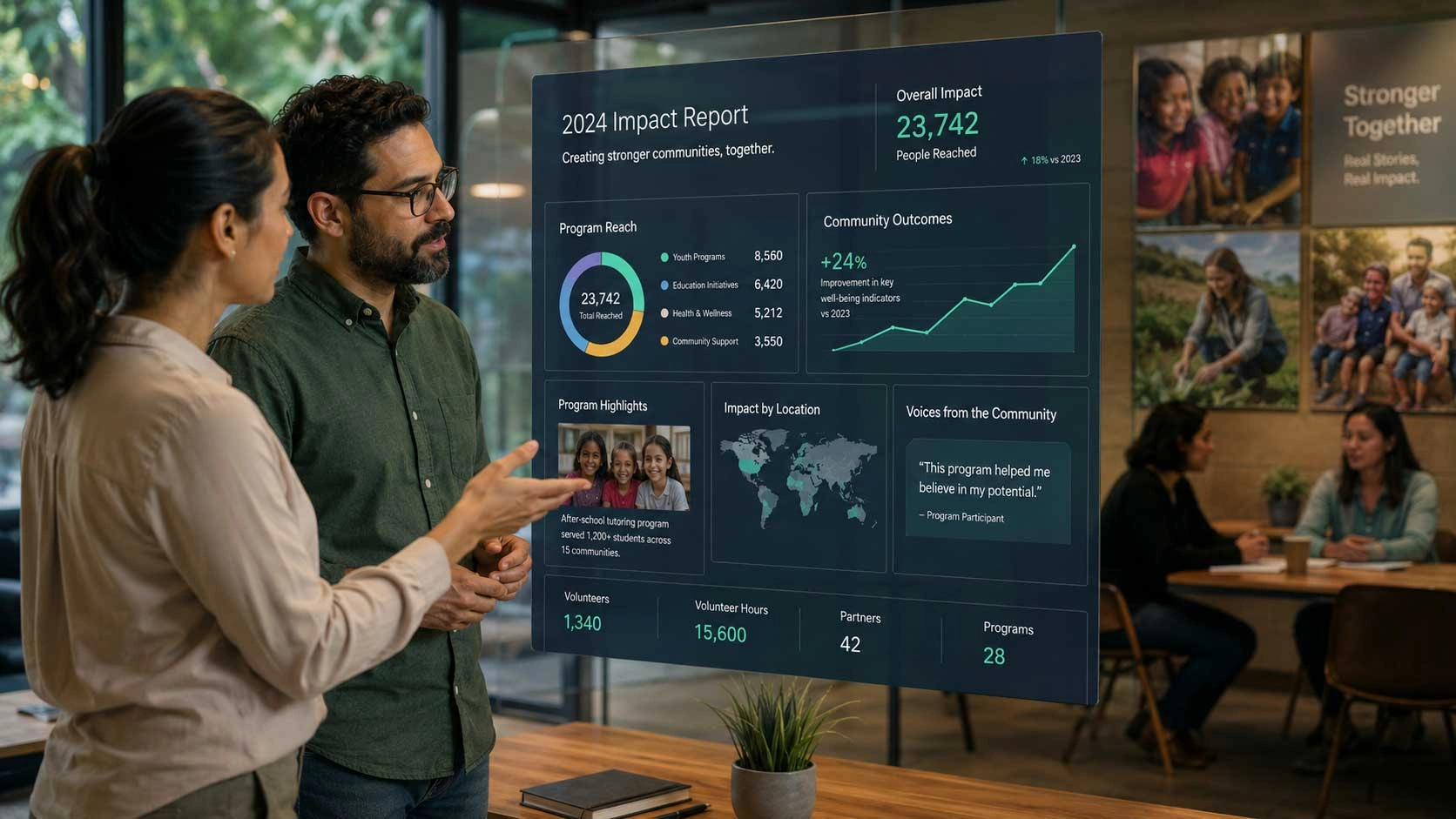
Enabled users to retrieve operational, financial, and project insights through natural language queries, transforming complex data analysis into instant, self-service intelligence.
See case studyWe work across the full LLM application stack — frontier and open-source models, fine-tuning and orchestration frameworks, vector databases, and deployment infrastructure — selecting the right combination for your accuracy, latency, cost, and data-residency requirements.
State-of-the-art models for reasoning, generation, and tool use.
Coordinate prompts, tools, and multi-step LLM workflows with reliability and control.
High-performance vector databases for semantic search and retrieval.
Store conversation history and long-term state for stateful LLM apps.
Modern languages and runtimes for building AI applications.
Connect to tools, APIs, and external systems seamlessly.
Monitor, trace, and evaluate AI systems in production.
Enterprise-grade cloud services and infrastructure foundations.
Enterprises trust VOCSO for LLM applications built to scale securely and meet regulatory standards. We design enterprise-grade AI systems that balance innovation with compliance across AWS, Azure, and Google Cloud.

General Data Protection Regulation

Information Security Management Systems

System and Organization Controls
For AI applications in healthcare

Responsible AI principles and implementation

AI Risk Management

Principles and implementations
India’s personal data protection framework

Auditability frameworks

Standards and evaluation practices
Validate an AI agent use case with a low-risk, fixed-scope engagement designed to prove value, feasibility, and ROI before committing to a full build.
 Dedicated AI Team
Dedicated AI TeamA cross-functional AI agent team embedded into your environment — working within your processes, security requirements, and communication tools.
End-to-end delivery of a defined AI agent capability with fixed scope, timeline, and commercial terms. Full knowledge transfer and documentation included.
Let's discuss the right engagement model for your project?
Book a callFirst-hand experiences from firms that shipped LLM applications with us, scaled intelligently, and achieved measurable results.
View all client testimonials“Vocso team has really creative folks and is very co-operative to implement client project expectations. MicroSave Consulting had great experience working with Anju and Prem.”

“Working with Deepak and his team at Vocso is always a pleasure. They employ talented staff and deliver professional quality work every time.”

“We love how our website turned out! Thank you so much VOCSO Digital Agency for all your hard work and dedication.”

“VOCSO SEO & SEM services helped me find new customers in a small budget. Their advanced SEO strategies made us visible to everyone.”

“Vocso team has really creative folks and is very co-operative to implement client project expectations. MicroSave Consulting had great experience working with Anju and Prem.”
“Working with Deepak and his team at Vocso is always a pleasure. They employ talented staff and deliver professional quality work every time.”
“We love how our website turned out! Thank you so much VOCSO Digital Agency for all your hard work and dedication.”
“VOCSO SEO & SEM services helped me find new customers in a small budget. Their advanced SEO strategies made us visible to everyone.”
The biggest cost and quality decisions in an LLM app are made at model selection — and the most expensive mistake is reaching for fine-tuning when a better prompt would have done.
There is no single best model. The right choice depends on your accuracy bar, latency budget, cost ceiling, and data-residency rules — and it changes as new models ship. We benchmark candidates on your data and adapt only when the evidence calls for it.
Benchmark on your data — We test candidate models against a labelled sample of your real inputs, scoring accuracy, latency, and cost per call — not vendor leaderboards.
Prompt before fine-tune — Most use cases are solved with prompting and RAG. We exhaust those first, because fine-tuning adds cost, data work, and a maintenance burden that isn't always justified.
Fine-tune when it pays — When accuracy or format consistency hits a ceiling, we use LoRA/QLoRA and instruction tuning to lift quality and often cut inference cost by moving to a smaller model.
Hosted vs. self-hosted — When data can't leave your perimeter, we deploy open models (Llama, Mistral) on your infrastructure; otherwise a hosted API may give the best accuracy per dollar.
At VOCSO, the model decision is made on benchmarked evidence and documented with its rationale — so it can be revisited as models, prices, and your requirements change.
Retrieval is where most LLM apps quietly fail. If the model is handed the wrong context, no prompt will save the answer — and the user gets confident, well-written nonsense.
Retrieval-augmented generation grounds the model in your data so it answers from facts, with citations, instead of its training memory. But naive RAG — embed everything, return top-k — performs poorly on real corpora. Reliable RAG is an engineering discipline.
Chunking & indexing — How documents are split, enriched with metadata, and indexed determines what can be retrieved. We tune chunking to your content, not a default.
Hybrid retrieval & re-ranking — We combine vector and keyword search, then re-rank results, so the model receives the most relevant context — not just the most semantically similar.
Citations & grounding — Answers link back to source passages, so users can verify them and you can audit them. Ungrounded claims are flagged, not surfaced as fact.
Retrieval evaluation — We measure retrieval quality (precision@k, recall, MRR) separately from generation, because a good answer starts with retrieving the right context.
VOCSO evaluates the retrieval layer independently before tuning generation — because in RAG, fixing the prompt can't fix a retrieval problem.
Treating prompts as throwaway text is why so many LLM apps are fragile — a tweak that helps one case silently breaks five others, and nobody notices until a user does.
In a production app, the prompt is code. It should be versioned, tested, and changed only with evidence. We engineer prompts the way we engineer software, not by trial and error in a playground.
Versioned & tested — Prompts live in source control and run against the eval set on every change, so we can prove a new version is better, not just different.
Structured outputs — We constrain the model to JSON or a defined schema and validate before use, so downstream code never has to parse free-form prose.
Few-shot & decomposition — Worked examples and breaking a hard task into smaller prompt steps lift reliability far more than a longer instruction ever will.
Token & cost discipline — Concise, well-structured prompts cut latency and cost at scale; we trim what doesn't earn its tokens without losing accuracy.
At VOCSO, every prompt change is measured against the eval suite before it ships — so improvements are real and regressions are caught before users see them.
Shipping an LLM app without an evaluation framework isn't a risk you take — it's a mistake you make. You simply have no way to know whether it works, or whether your last change broke it.
A model that sounds confident is not necessarily correct, and an app that nailed the demo is not necessarily reliable on the edge cases real users generate. Evaluation is how you find those gaps before they do — and how you keep finding them after launch.
Labelled test set — We build a representative set of real inputs with expected outputs, so accuracy is a number measured against ground truth, not a gut feeling.
Task & output accuracy — Does the app produce correct, correctly-formatted results across the test set? Measured per task type, tracked on every change.
Hallucination & grounding checks — For RAG and generation, we measure whether claims are supported by the source — and flag those that aren't before they reach users.
Regression & failure-mode coverage — Every prompt, model, or retrieval change is re-run against the suite, so a fix in one place can't silently break another.
No VOCSO LLM app ships without passing its evaluation benchmark. We define the success criteria at the start of the project — not after the first production failure.
A capable LLM app without guardrails is a liability — it will eventually hallucinate, leak, or run up a bill nobody approved. Production-readiness is what you build around the model.
Guardrails, safety, and cost control are not optional polish; they are what separate an app you can put in front of customers from a demo you keep behind a login. They have to be engineered, monitored, and enforced in the runtime — not described in a prompt and hoped for.
Input & output guardrails — We filter unsafe or off-topic inputs, validate outputs against a schema, and block or escalate low-confidence answers before they reach a user.
Prompt-injection defence — User and document content is treated as untrusted; we test against injection attempts designed to override the app's instructions or exfiltrate data.
Cost & latency control — Model routing, caching, and prompt compression keep spend and response times predictable as volume grows — cheap models for easy cases, the strong model only when needed.
Monitoring & audit trail — Every request, response, cost, and latency is logged, so you can trace any output, watch for drift, and answer a regulator's or client's questions with evidence.
VOCSO builds guardrails and cost controls into the application runtime from day one — so the app stays safe, accountable, and affordable as it scales, not just on launch day.
The prototype proved the idea works once. Production is the promise that it works every time, for real users, on messy inputs — and that's a different, larger job than the demo suggested.
Crossing that gap is where most LLM projects stall, because the work isn't visible in a demo: it's the reliability, evaluation, and operability nobody scopes upfront. We plan for it from the first sprint, so the prototype becomes the first stage of a real system rather than a dead end.
Harden against real inputs — We move the app off the happy path and onto your actual data — the scans, the typos, the edge cases — and fix what breaks before users find it.
Wire in evaluation & monitoring — An eval suite plus production monitoring means you catch quality regressions and drift before customers do, including when a provider updates the model underneath you.
Define the operating model — Who owns it, how incidents are handled, how prompts and models are updated — production AI needs an owner and a runbook, not just a launch date.
Ship behind a measurable bar — We agree the accuracy, latency, and cost targets the app must hit to go live, so 'ready for production' is a number you can check, not a feeling.
VOCSO treats the prototype as the first slice of a production system — so the path from 'it works in a demo' to 'it runs reliably for everyone' is a continuation, not a rebuild from scratch.
You delivered exactly what you said you would in exactly the budget and in exactly the timeline.





Most teams start with one high-value use case — typically document intelligence, an internal copilot, or a customer-facing assistant. We help you scope, build, and prove it in 6 weeks, with an accuracy target defined upfront. No open-ended contracts. No ambiguous scope.
deepak@vocso.com — no forms, no funnels.
This is one of the most common reasons firms come to us. A prototype that impressed on clean inputs but fell apart on real data almost always lacks three things: an evaluation framework, grounding and guardrails, and cost control. We assess what you already have, agree the accuracy target it has to hit, and engineer the missing layers to take it from promising demo to production-grade — often without starting over.
Cost tracks with complexity, integrations, and whether fine-tuning is needed. A focused single-use-case app typically runs $15,000–$40,000; a multi-feature production application with RAG, integrations, and full evaluation and guardrails runs $40,000–$120,000+. We usually start with a fixed-price PoC (typically $12,000–$20,000) that proves value on your real data before you commit to the full build, and every engagement opens with a free 30-minute call to scope and estimate honestly.
A production-ready LLM application typically takes 10–14 weeks: roughly 2 weeks of discovery and design, 5–6 weeks of model/prompt foundation and build, 2 weeks of evaluation and guardrails, then pilot and production. A scoped PoC runs in about 6 weeks. The two biggest variables are how ready your data is and whether fine-tuning is required — both of which we settle in discovery so the timeline you're given is real.
Most use cases are solved with strong prompting plus RAG, and we exhaust those first, because fine-tuning adds data work, cost, and ongoing maintenance. We reach for fine-tuning (LoRA/QLoRA, instruction tuning) when accuracy or output-format consistency hits a ceiling prompting can't clear, or when it lets us move to a smaller, cheaper model without losing quality. It's a decision made on benchmarked evidence against your evals, never on preference.
It comes down to your constraints. Hosted API models (GPT, Claude, Gemini) usually give the best accuracy per dollar and the fastest start. Self-hosted open-weight models (Llama, Mistral, Qwen) are the answer when data can't leave your infrastructure, or when high volume makes a fine-tuned smaller model far cheaper to run. We benchmark both against your accuracy, latency, cost, and data-residency requirements and document why we landed where we did — and we build so you can switch later without a rebuild.
Nobody eliminates hallucination, so we engineer it down and box it in: RAG grounding so answers come from your source documents with citations a user can check; structured-output validation against a schema; confidence thresholds that route shaky answers to human review; and hallucination-specific cases in the eval suite. We agree an acceptable error rate for the use case up front and monitor it in production — so the question becomes 'is it within the limit we set?', which is one you can actually answer.
With an evaluation framework built before the app ships — it's the least glamorous deliverable and the most important. We assemble a labelled test set of real inputs and expected outputs, then score accuracy, output validity, retrieval quality (for RAG), and hallucination rate against it. Every prompt, model, or retrieval change is re-run on the suite, so improvements are provable and regressions are caught before users see them. Quality stops being a feeling and becomes a number you can move.
Inference cost is an architecture decision, not a line item you optimise later. We route easy requests to cheap models and reserve the expensive one for genuinely hard cases, cache what repeats, compress prompts, and — where it pays off — fine-tune a smaller model. Cost-per-request is modelled during the build and watched in production like any other metric, so spend stays predictable as volume grows instead of becoming the reason finance switches the product off.
Yes — secure access to your data is core to most LLM apps. We use least-privilege access, keep data inside your defined perimeter (including self-hosted/VPC deployments when required), avoid sending sensitive data to third-party models where policy forbids it, and log every access. We also treat all user and document content as untrusted and test against prompt-injection attempts designed to override the app's instructions or exfiltrate data — with input filtering, output validation, and strict separation of instructions from content, enforced in the runtime rather than asked for in a prompt. This satisfies most enterprise security reviews and aligns with ISO 27001 controls.
Yes to both. We connect LLM apps to Salesforce, HubSpot, SharePoint, SAP, Oracle, ServiceNow, Jira, and most enterprise platforms via their APIs, plus your databases and document stores; for systems without clean APIs we build structured wrappers. And because embedded assistants get far higher adoption, we surface the app where your users already work — inside your own product UI, or via Microsoft Teams, Outlook add-ins, and SharePoint — all driven by the same backend whether it runs standalone or embedded.
Yes — and it matters, because LLM apps drift as providers update models and as inputs change, so an app accurate at launch can degrade quietly. Every engagement includes 90 days of post-launch support (monitoring, eval tracking, prompt tuning, minor adjustments), with the evaluation suite running against production to catch regressions and re-validate before any new model version is adopted. Beyond that, retainers cover model-update validation, drift monitoring, new features, and integration maintenance as your systems and the model landscape move.
Completely. All code, prompts, fine-tuned model weights, evaluation sets, and documentation are yours, unconditionally. We sign NDAs before any discovery conversation, retain no client data after a project concludes, and never use your data to train models for anyone else. For stricter requirements we work inside your cloud environment so we never hold your production data at all — you're left owning the app and the data advantage underneath it.
Discover complementary services that complete your LLM application — from RAG and fine-tuning to agents, integration, and AI strategy.