15+ Years
Enterprise software delivery since 2009 — a track record built across technology cycles, not just the current AI wave.


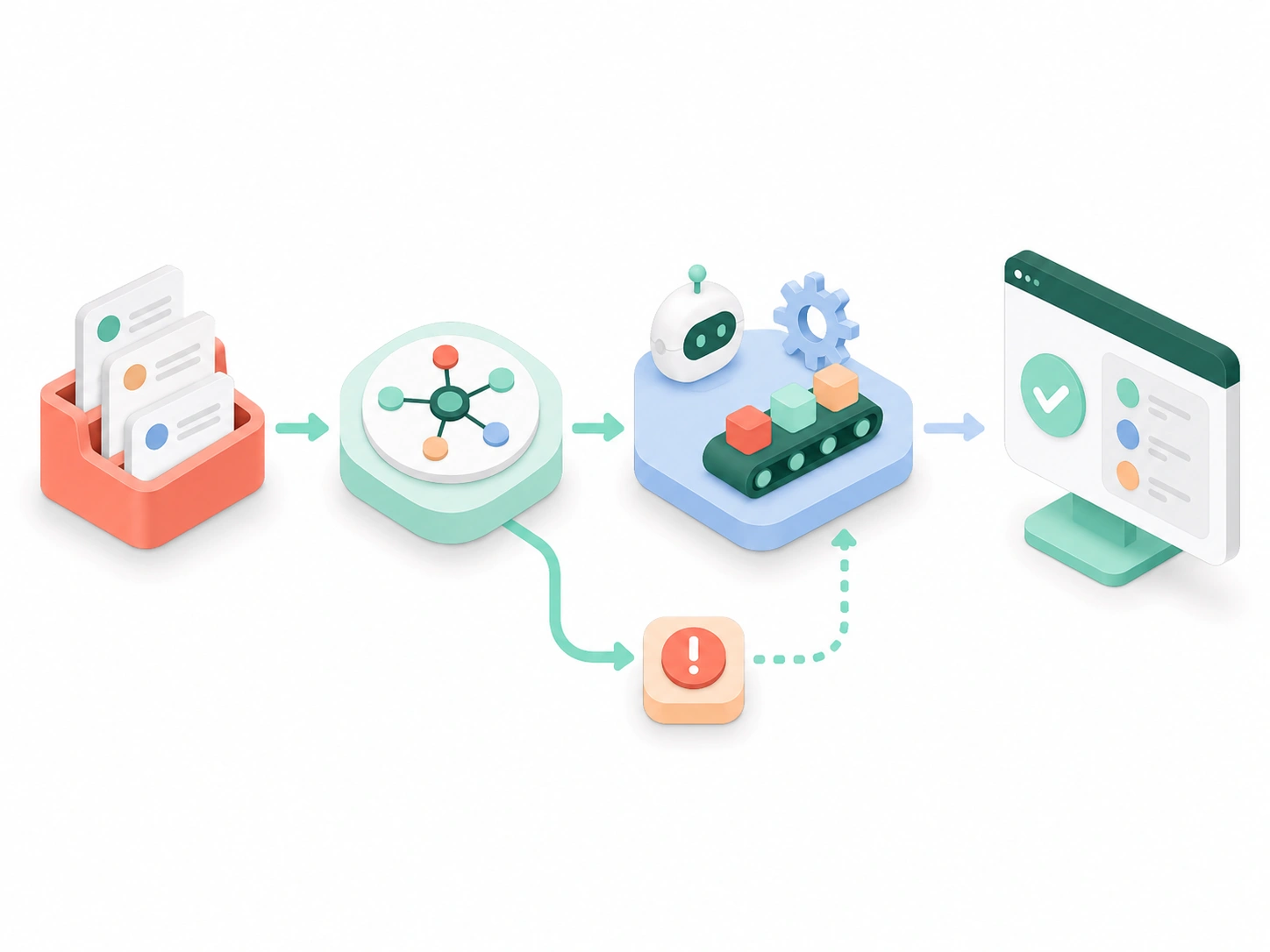
Fine-tuning is the lever teams reach for too early and avoid too late. We start by telling you whether you even need it — then, when the evidence says yes, we adapt an open model to your task so a smaller, cheaper model matches a frontier giant on your data. LoRA, QLoRA, and full fine-tuning, built on a curated dataset you own, benchmarked against your current baseline, and served on your own infrastructure. Lower cost per call, accuracy past the prompting ceiling, no vendor lock-in.


A decade of AI engineering experience, validated in numbers

Fine-tuning is one piece of a production LLM app — engineered with evaluation, guardrails, and serving around the model, not just a set of weights handed over.
The other lever: when the gap is missing or changing facts, RAG supplies them at query time. Often the right answer is fine-tuning plus RAG — and we build both.

Fine-tuning is applied ML — the same training, evaluation, and MLOps discipline behind every model we build, including the non-LLM ones.
For high-volume, well-defined text tasks, a fine-tuned small model is often the cheapest path — part of the broader NLP toolkit we build for classification and extraction.
Fine-tuned models power custom generative features — drafting, rewriting, structured generation — tuned to your voice, format, and domain.

A fine-tuned model only earns its keep once it's wired into your systems and workflows — integration is where the accuracy and cost gains actually land.

Fine-tuned models make agents more reliable and cheaper to run at scale — consistent tool-calling and output formats baked into the model itself.

Not sure fine-tuning is the right move, or where it pays off? Strategy and a costed roadmap — including the build/buy/fine-tune call — before you commit.
Parameter-efficient fine-tuning that adapts a model on a fraction of the compute — most of the accuracy of full fine-tuning, at a small fraction of the cost and training time.

Teach a model to follow your specific instructions, output formats, and tone reliably — turning inconsistent responses into the structured, on-brand outputs your application depends on.

The work that decides everything — curating, cleaning, and formatting training examples, and bootstrapping data with a larger model where you're short. Quality data beats more data, every time.
Our fine-tuned models are tailored to the language, accuracy bar, and cost constraints of each industry.
Consulting & Advisory Fine-tune models on your methodology, past deliverables, and terminology so outputs match your firm's voice and standards.
Trusted by Rodic Consultants
SaaS & Digital Platforms. Fine-tune a smaller model to power product AI features at a cost that scales with your users, not against them.
Engineering & Infrastructure. Adapt models to technical language, standards, and specs so they understand your domain's vocabulary precisely.
Financial Services. Fine-tune models on financial language and compliance requirements — accurate, consistent, and runnable inside your perimeter.
Supply Chain & Logistics. Adapt models to your documents, codes, and terminology for accurate extraction and classification at volume.
Healthcare & Research. Fine-tune open models on clinical and research language — kept entirely within your infrastructure for privacy and compliance.
CleanTech & Mobility. Adapt models to technical and regulatory language across energy and mobility for accurate, cost-efficient processing.
EdTech Platforms. Fine-tune models on your curriculum and pedagogy so AI features speak your subject and grade level accurately.
Non-Profits & Foundations Fine-tune efficient open models so AI features fit limited budgets without per-call API costs.








We combine deep model-training expertise with enterprise delivery practices to ship fine-tuned models that are more accurate, cheaper to run, and yours to keep.
Enterprise software delivery since 2009 — a track record built across technology cycles, not just the current AI wave.
Independently certified, annually audited — meets the security baseline enterprise procurement actually checks.

Nine in ten enterprise clients return for follow-on work — the only measure of delivery quality that cannot be faked.

Verified client reviews, independently collected — real feedback from real enterprise engagements.

Certified cloud partnerships with AWS and Microsoft Azure — enterprise infrastructure standards from day one.

DataSense, DocSense, BidSense — proprietary pre-built AI products that go live in weeks, not months of custom build.

IP, data, and strategy protected before the first discovery call ends — not after contracts are signed.

Post-deployment optimisation included in every engagement — we stay accountable until the system is performing.

Fine-tuning is the most misunderstood lever in AI — reached for when a prompt would do, avoided when it's exactly right. Here are the truths that decide whether it earns its place, or burns your budget on a model no better than the one you started with.
The instinct to fine-tune is often a reflex, not a decision. Most of the time a sharper prompt or retrieval (RAG) solves the problem faster and cheaper — and the single most valuable thing we do on a fine-tuning engagement is sometimes tell you not to fine-tune yet.

If a clearer prompt, a few good examples, or retrieval over your documents gets you there, that's hours of work instead of weeks — and nothing to retrain when things change. We always push prompting and RAG to their real ceiling before recommending training, because fine-tuning a problem a prompt could fix is wasted budget and a model you now have to maintain.
The opposite mistake is just as common: paying premium API rates forever for a high-volume task a fine-tuned small model would handle for a fraction, or accepting an accuracy ceiling prompting can't break. Refusing to fine-tune when the evidence says you should is a slow, recurring cost — not a saving.
The real expertise isn't running a training script — it's diagnosing whether your problem is a prompt problem, a knowledge problem, or a behaviour problem, because each has a different fix. That diagnosis is the first thing we do, before any GPU is booked, so you spend on the lever that actually moves your metric.
Teams obsess over which base model and which technique. But the result is decided almost entirely by the quality of the examples you train on — fine-tuning is a data-curation project with a training step at the end, and a model trained on messy data faithfully learns the mess.

A fine-tuned model is a mirror of its training set — including its inconsistencies, mislabels, and bad habits. Garbage examples don't average out; they get baked in. That's why a vendor who skips straight to training is dangerous: the work that determines the outcome happens before the GPU ever spins up.
You don't need millions of examples — for LoRA, hundreds to low thousands of clean, consistent ones usually beat a huge noisy pile. A few hundred examples that all demonstrate the behaviour the same way teach more than ten thousand that contradict each other. Curation, not collection, is the job.
Short on examples? We use a larger model to draft training data that humans then review and correct, plus augmentation for the rare cases — a far faster path to a usable set than hand-writing everything. You're rarely as far from enough data as you think.
Your curated training set outlives any single base model: when a better open model ships, you re-tune on the same data and inherit the gains. We treat that dataset as a proprietary asset you own and grow — the part of the work with lasting value.
A fine-tuned model that nobody compared to what you already had is a leap of faith, not an improvement. The only way to know fine-tuning worked is to measure it against your current model on a held-out set — and surprisingly often, that measurement is never taken.
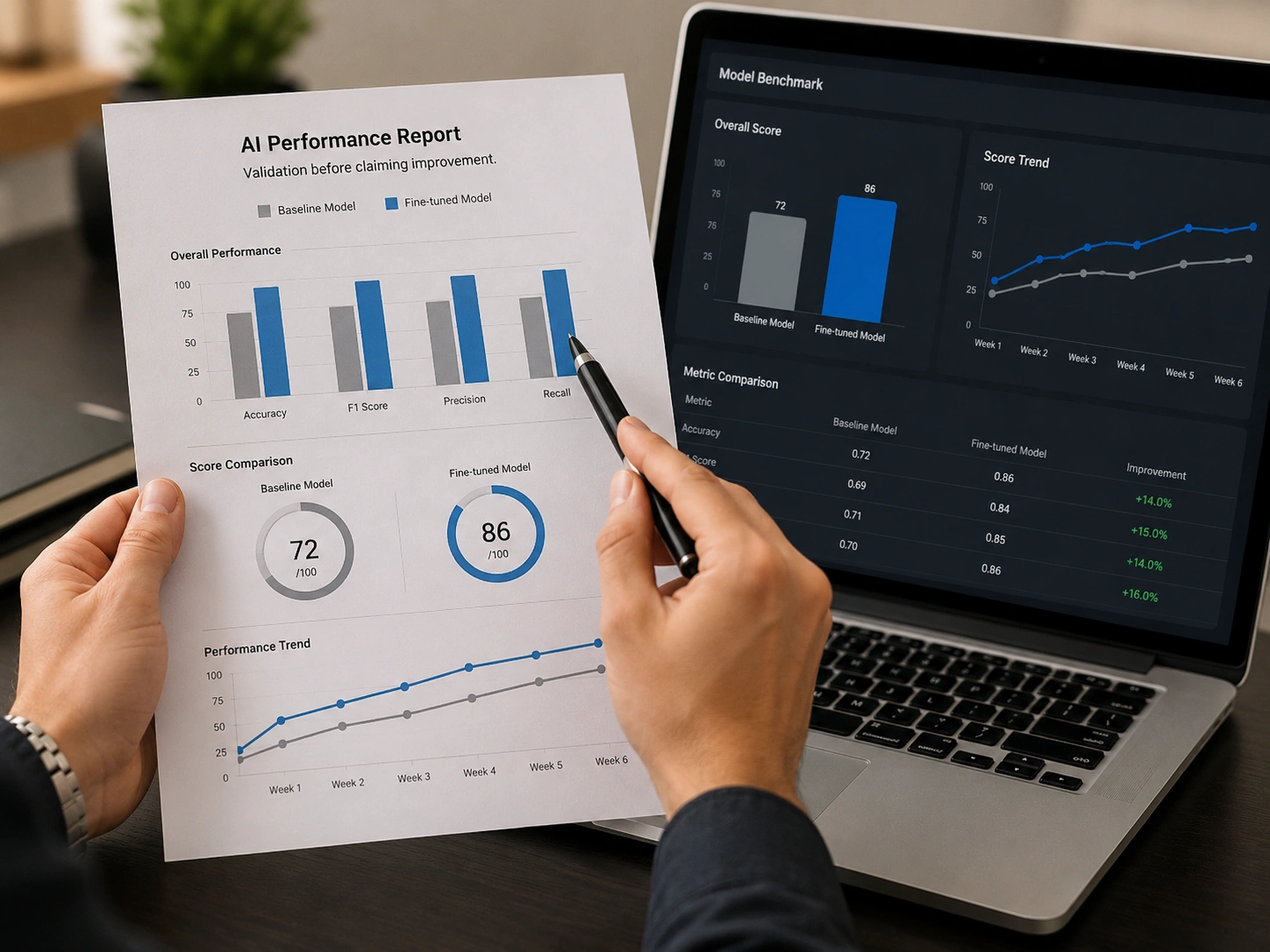
Before training anything, we establish how your current setup — the base model with your best prompt, or your existing solution — actually performs on a held-out test set. That baseline is the number the fine-tuned model has to beat. Without it, "it seems better" is the best anyone can honestly say, and that's not good enough to ship on.
Accuracy measured on data the model trained on is meaningless — it memorised those. We evaluate on examples held back from training, so the number reflects how it behaves on inputs it'll actually meet in production, not how well it recited its homework.
You get the before-and-after on the same test set, including the cases where it didn't help. Sometimes the honest answer is that fine-tuning gained little and a prompt change would do — and we'd rather tell you that than hand you a model with no evidence it's worth deploying.
The fastest way to judge a fine-tuning vendor is to ask exactly that. A serious partner answers with a number on your data; one who can't quote the improvement either didn't measure it or doesn't want you to — and either way you're buying blind.
The three levers — prompting, RAG, and fine-tuning — solve genuinely different problems, and most "should we fine-tune?" debates are really a mix-up about which problem you have. Get the distinction right and the answer is usually obvious.

The cheapest lever, and the one to try first. If the model can do the task but needs clearer instructions or a few examples, prompt engineering gets you there with no training and no data to curate. A surprising share of "we need fine-tuning" turns out to be "we need a better prompt".
When the gap is missing or changing facts — your documents, your latest data — retrieval supplies them at query time. It's the right tool for knowledge that updates, where baking facts into weights would be expensive and stale within weeks. Don't fine-tune facts that change.
When you need a consistent output format, a domain's language and tone, or a specific skill baked in — or a smaller model to match a bigger one's quality — fine-tuning teaches behaviour that prompting can't reliably reach. It changes the model itself, not just its inputs, which is exactly why it needs data and proof.
The strongest systems fine-tune for behaviour and cost, add RAG for fresh facts, and reach both through good prompting. We design the mix for your task rather than selling you the one lever we happen to lead with — and a focused PoC proves the combination before you commit to a full build.
The headline payoff of fine-tuning isn't a slightly smarter model — it's a small, cheap one that matches a frontier giant on your specific task. Because the saving repeats on every single call, at production volume it's the economics, not the accuracy, that usually justify the project.

A general-purpose giant is paying — in money and latency — for a breadth you don't need on one narrow task. A smaller open model fine-tuned for that task can match it where it counts, and every inference is dramatically cheaper. Multiply that by production volume and the per-call gap becomes the whole business case.
When a model fundamentally misreads your domain's language, format, or edge cases, prompting and RAG plateau — you can feel the accuracy refusing to climb past a certain point. Fine-tuning teaches the model your world directly, which is how you clear a ceiling no amount of prompt rewriting will move.
A model that returns the right format most of the time still breaks the system consuming it. Instruction tuning makes the correct behaviour consistent, so you can drop the brittle re-parsing and retries that were quietly failing in production — reliability is often a bigger win than raw accuracy.
A fine-tuned open model runs on your infrastructure, inside your perimeter — strong domain-specific AI without sending sensitive data to a third-party API. The model and its training data are yours to keep, re-tune, and improve as your data grows, instead of renting capability by the call forever.
A folder of fine-tuned weights is not a working system. The value only shows up once the model is served efficiently, integrated, monitored, and re-tuned as your data shifts — and a vendor who hands over weights and walks away has handed you the hard 80% of the job.

A fine-tuned model has to be quantised, optimised, and served so it actually hits the latency and cost targets that justified building it. A model that's accurate but too slow or expensive to run in production isn't a win — getting it to run economically is engineering work, not an afterthought.
Your data, formats, and use cases change, and a static fine-tuned model slowly falls out of step. We track its performance against your benchmark over time so you see quality slipping before it becomes a problem — not after a downstream system starts failing on it.
Because your curated dataset is an owned asset, refreshing the model is a re-train on more data, not a rebuild — and when a stronger base model ships, you inherit its gains on the same data. We set up that loop so the model keeps improving instead of decaying after handover.
The weights, the training data, the serving setup, and the evaluation harness are all yours — running on your infrastructure, free of lock-in. That ownership is what turns a one-off project into a compounding capability you control for years.
Weeks 1–2
We define the task, confirm fine-tuning is the right lever, and set the accuracy and cost targets — before any training begins.
Weeks 3–5
We curate, clean, and format the training data — the work that determines the quality of the result.
Weeks 5–8
We fine-tune the model — LoRA/QLoRA or full — tuning hyperparameters to your task.
Weeks 8–9
We benchmark the fine-tuned model against your baseline on a held-out set, and prove the gain.
Weeks 9–12
We deploy the model with optimised serving and monitoring, on your infrastructure, and set up re-tuning as your data grows.
Book a free 30-minute discovery call with a senior AI engineer — no slide deck, just questions about your task, your data, and your goals.
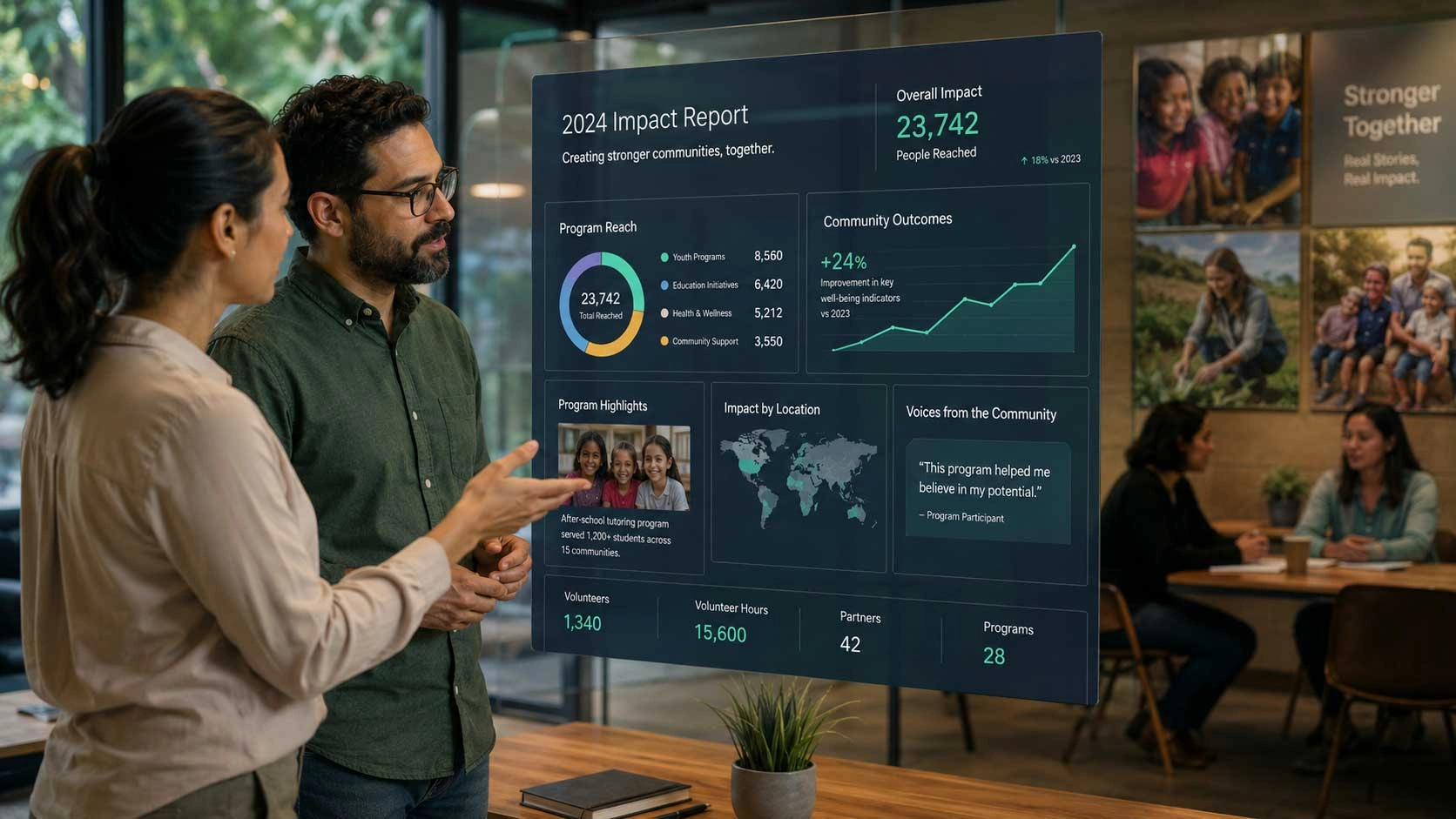
Enabled users to retrieve operational, financial, and project insights through natural language queries, transforming complex data analysis into instant, self-service intelligence.
See case studyWe fine-tune on a proven stack — open and frontier models, training and PEFT frameworks, experiment tracking, optimised serving runtimes, and cloud or on-prem infrastructure — selecting the right combination for your task, accuracy target, and cost requirements.
State-of-the-art models for reasoning, generation, and tool use.
Fine-tune and train models efficiently — full, LoRA, and QLoRA.
High-performance vector databases for semantic search and retrieval.
Track training runs, compare checkpoints, and version fine-tuned models.
Modern languages and runtimes for building AI applications.
Connect to tools, APIs, and external systems seamlessly.
 PyTorch
PyTorch
Monitor, trace, and evaluate AI systems in production.
Enterprise-grade cloud services and infrastructure foundations.
Enterprises trust VOCSO for fine-tuned models built to scale securely and meet regulatory standards. We train on your data with privacy and compliance engineered in — including fully self-hosted models — across AWS, Azure, Google Cloud, and on-prem.

General Data Protection Regulation

Information Security Management Systems

System and Organization Controls
For AI applications in healthcare

Responsible AI principles and implementation

AI Risk Management

Principles and implementations
India’s personal data protection framework

Auditability frameworks

Standards and evaluation practices
Validate an AI agent use case with a low-risk, fixed-scope engagement designed to prove value, feasibility, and ROI before committing to a full build.
 Dedicated AI Team
Dedicated AI TeamA cross-functional AI agent team embedded into your environment — working within your processes, security requirements, and communication tools.
End-to-end delivery of a defined AI agent capability with fixed scope, timeline, and commercial terms. Full knowledge transfer and documentation included.
Let's discuss the right engagement model for your project?
Book a callFirst-hand experiences from firms that fine-tuned models for their domain and achieved measurable results.
View all client testimonials“Vocso team has really creative folks and is very co-operative to implement client project expectations. MicroSave Consulting had great experience working with Anju and Prem.”

“Working with Deepak and his team at Vocso is always a pleasure. They employ talented staff and deliver professional quality work every time.”

“We love how our website turned out! Thank you so much VOCSO Digital Agency for all your hard work and dedication.”

“VOCSO SEO & SEM services helped me find new customers in a small budget. Their advanced SEO strategies made us visible to everyone.”

“Vocso team has really creative folks and is very co-operative to implement client project expectations. MicroSave Consulting had great experience working with Anju and Prem.”
“Working with Deepak and his team at Vocso is always a pleasure. They employ talented staff and deliver professional quality work every time.”
“We love how our website turned out! Thank you so much VOCSO Digital Agency for all your hard work and dedication.”
“VOCSO SEO & SEM services helped me find new customers in a small budget. Their advanced SEO strategies made us visible to everyone.”
The biggest mistake in fine-tuning is doing it when you didn't need to. These three approaches solve different problems — and starting with the wrong one wastes money and time.
We work through them in order of cost, only escalating when the simpler lever genuinely can't reach the goal.
Prompting — what you ask — If the model can do the task but needs clearer instructions or examples, better prompting gets you there with no training and no data. Always the first thing to try.
RAG — what it knows — When the gap is missing or changing facts, retrieval supplies them at query time. Right for knowledge that updates; fine-tuning facts in would be costly and quickly stale.
Fine-tuning — how it behaves — When you need a consistent format, a domain's language, or a cheaper model to match a bigger one, fine-tuning teaches behaviour prompting can't reliably reach.
Usually a combination — Many production systems fine-tune for behaviour and cost, then add RAG for fresh facts — we design the mix, not a single lever.
At VOCSO, we'll tell you honestly when fine-tuning isn't the answer — because recommending training you don't need is how vendors lose trust, and we'd rather keep it.
Fine-tuning used to mean retraining billions of parameters on expensive hardware. LoRA and QLoRA changed the economics — you can now adapt a capable model for a fraction of the cost and time.
Parameter-efficient fine-tuning trains a small number of new weights on top of a frozen base model, capturing most of the benefit of full fine-tuning at a sliver of the resource.
LoRA — adapt, don't retrain — We train small low-rank adapters instead of the whole model, so a fine-tune that would need a cluster runs on a single GPU.
QLoRA — quantised and cheaper still — Quantising the base model shrinks memory needs further, putting fine-tuning of large models within reach on modest hardware.
When full fine-tuning is worth it — For the deepest specialisation or continued pre-training on large corpora, full fine-tuning earns its cost — and we'll say when that's the case.
Swappable adapters — LoRA adapters can be kept separate and swapped per task, so one base model can serve several fine-tuned behaviours without duplicating it.
At VOCSO, we default to the most efficient method that hits your accuracy target — because spending on full fine-tuning when LoRA would do is burning budget for no extra result.
Fine-tuning is 90% data work and 10% training. A model fine-tuned on a few hundred excellent examples beats one trained on thousands of mediocre ones — every time.
The model learns exactly what your data teaches it, mistakes included. So the real engineering is in the examples, not the training run.
Quality over quantity — A small set of clean, correct, representative examples outperforms a large noisy one. We curate ruthlessly rather than scraping everything we can find.
Cover the real distribution — The training data has to include the hard and rare cases, not just the easy majority, or the model fails exactly where you needed it most.
Bootstrap when you're short — Where you lack examples, we use a larger model to generate and you to review candidate data — reaching enough volume without months of manual labelling.
Consistent formatting — Inconsistent examples teach the model to be inconsistent; we standardise format and labels so the model learns one clear behaviour.
At VOCSO, most of the engagement goes into the data — because the surest way to a disappointing fine-tune is to rush the dataset to get to the training.
The headline reason enterprises fine-tune is cost. A fine-tuned smaller model can match a frontier model on one task — and at production volume, the per-call saving is the whole business case.
When you only need a model to do your task, you're paying a premium for a giant model's general ability you'll never use. Fine-tuning lets a small model specialise and close the gap.
Match the bar with a smaller model — Fine-tuned on your task, a small open model often equals a frontier API model's quality — at a fraction of the per-call cost.
50–70% lower inference cost — That's a typical saving when replacing a premium API model with a fine-tuned one for a defined task — and it compounds with every call.
Predictable, owned economics — Self-hosting a fine-tuned model turns variable per-token API bills into a fixed, controllable infrastructure cost.
We model the break-even — Fine-tuning has an upfront cost; we calculate the volume at which it pays back, so the decision is made on numbers, not faith.
At VOCSO, we quantify the cost case before you commit — because fine-tuning for savings only makes sense when the volume justifies the upfront investment, and we'll tell you when it does.
The question that matters after fine-tuning is simple and often skipped: is it actually better than what you had? Without a baseline and a held-out test, you can't answer it — and you might ship a model that's different, not better.
Evaluation is how fine-tuning stays honest. We prove the gain rather than assuming it.
Benchmark against the baseline — We measure the fine-tuned model against the model (or prompt) you use today, on the same held-out set, so the improvement is a real, attributable delta.
A held-out test set — Evaluation runs on data the model never trained on, so the score reflects real performance, not memorisation of the training examples.
Accuracy and cost together — We compare both quality and cost-per-call, because the win is usually a balance — equal accuracy far cheaper, or higher accuracy at acceptable cost.
Catch the regressions — Fine-tuning can improve one thing and quietly break another; we test broadly enough to catch that before it reaches production.
No VOCSO fine-tune ships without beating its baseline on your evaluation set — because 'we fine-tuned a model' is not the same as 'we made it better,' and only the second is worth paying for.
Fine-tuning has two classic failure modes that turn a promising model into a worse one: overfitting to your examples, and forgetting the general ability that made the base model useful. Both are avoidable — if you build for them.
A model that aced the training set but fails on anything slightly different, or that nails your task but can no longer do basic things, isn't an improvement. We engineer to prevent both.
Overfitting — memorising, not learning — Train too hard on too little data and the model parrots the examples instead of generalising. We use validation monitoring, early stopping, and the right data volume to prevent it.
Catastrophic forgetting — Aggressive fine-tuning can erase the base model's general skills. Parameter-efficient methods (LoRA) and careful tuning preserve what made the model capable in the first place.
Held-out and broad testing — We test on unseen data and on capabilities outside the fine-tuned task, so we catch both failure modes before deployment, not after.
Right-sized training — The fix is often restraint: the correct learning rate, epochs, and method for your data size — not more training, which usually makes both problems worse.
At VOCSO, we tune deliberately to keep the model both specialised and capable — because a fine-tune that wins on your task but breaks everything else isn't a model you can ship.
You delivered exactly what you said you would in exactly the budget and in exactly the timeline.





Most teams start with one high-value task — where a general model is too expensive, too inconsistent, or just not accurate enough. We fine-tune, benchmark against your baseline, and prove the gain in 6 weeks. No open-ended contracts. No ambiguous scope.
deepak@vocso.com — no forms, no funnels.
Prompt first — it's free and fast. Use RAG when the gap is missing or changing facts. Fine-tune when you need consistent behaviour or format, a model that genuinely understands your domain's language, or a smaller, cheaper model to match a large one on a specific task. Often the answer is a combination. We assess which lever fits before recommending training — and the most valuable thing we sometimes do is tell you not to fine-tune yet.
Cost depends mainly on data preparation and the method, not the compute. A focused LoRA fine-tune on a well-defined task typically runs $15,000–$40,000; larger programmes — full fine-tuning, multiple tasks, continued pre-training, and deployment — run $40,000–$120,000+. The training run is often a small part; the data work dominates. We usually start with a fixed-price PoC (typically $12,000–$20,000) to prove the gain first, and every engagement opens with a free 30-minute discovery call.
A production fine-tuning project typically takes 8–12 weeks: roughly 2 weeks discovery and approach selection, 3–4 weeks data preparation, 2–3 weeks training and evaluation, then deployment. A scoped PoC runs in about 6 weeks. The biggest variable is training-data readiness — the training run itself is usually fast; preparing good data is the work.
Less than most people expect. For LoRA/QLoRA on a focused task, a few hundred to a few thousand high-quality examples is often enough — quality and consistency matter far more than quantity. We assess what you have and, where you're short, bootstrap examples with a larger model and your review. We won't let the lack of a massive dataset block the project.
When you replace a premium frontier-API model with a fine-tuned smaller open model on a specific task, inference cost typically drops substantially — often by a half to two-thirds — and because the saving repeats on every call, at production volume it compounds into the main business case. We model the break-even (upfront fine-tuning cost vs. ongoing saving) on your real volume so the decision is made on numbers, not a brochure figure.
We benchmark it against your current baseline — your existing model or prompt — on a held-out test set the model never trained on, and report the delta in accuracy and cost. If it doesn't beat the baseline, it doesn't ship. We define the success metric with you before training, so 'better' is a measured number, not an assumption, and you can see exactly what you're deploying.
This is the most common misconception. Fine-tuning teaches behaviour and patterns — it's the wrong tool for facts that change, which go stale in the weights, and only a partial fix for hallucinations. For current information and factual grounding, RAG (retrieving and citing source data at query time) is the stronger tool. Most robust systems fine-tune for how the model behaves and use RAG for what it needs to know, and we design that split.
Open models like Llama, Mistral, Qwen, and Gemma (which we fine-tune and self-host), and hosted models with fine-tuning APIs (e.g. OpenAI, Google). We pick the base model on your accuracy target, deployment needs, and whether data must stay in your environment — which usually points to an open model you host. We also fine-tune for the specific languages your task needs, including multilingual models, and test quality per language rather than assuming it transfers — domain fine-tuning is often especially valuable in non-English settings where general models are weaker.
Yes to both — it's a core reason to fine-tune an open model. We can run the entire process inside your infrastructure or VPC, so training data never leaves your environment, and deliver a model you host yourself. And ownership is complete: the fine-tuned weights (or adapters), the curated training data, the code, and the documentation are yours unconditionally — a lasting asset that improves as you add data. We sign NDAs before any discovery conversation and never reuse your data for anyone else.
With validation monitoring and early stopping to prevent overfitting, parameter-efficient methods (LoRA) and careful learning rates to preserve the base model's general ability, and broad testing — on unseen data and on capabilities outside the target task — to catch both before deployment. Often the fix is restraint, not more training.
Often, yes. If you have a fine-tune that underperformed — overfitted, forgot too much, or was never properly evaluated — we assess it and frequently fix it through better data, the right method, or careful re-tuning, rather than starting over. We'll tell you honestly when a fresh start is the cheaper path.
Yes. Every engagement includes 90 days of post-launch support — monitoring and adjustments. Beyond that we offer retainers covering performance monitoring, periodic re-tuning as your data grows or your task evolves, and base-model upgrades (when a stronger open model ships, you re-tune on the same data and inherit the gains). A fine-tuned model gets better with iteration, and we set up the pipeline to keep improving it rather than letting it drift.
Discover complementary services that pair with your fine-tuned model — from LLM apps and RAG to MLOps, machine learning, and NLP.