15+ Years
Enterprise software delivery since 2009 — a track record built across technology cycles, not just the current AI wave.


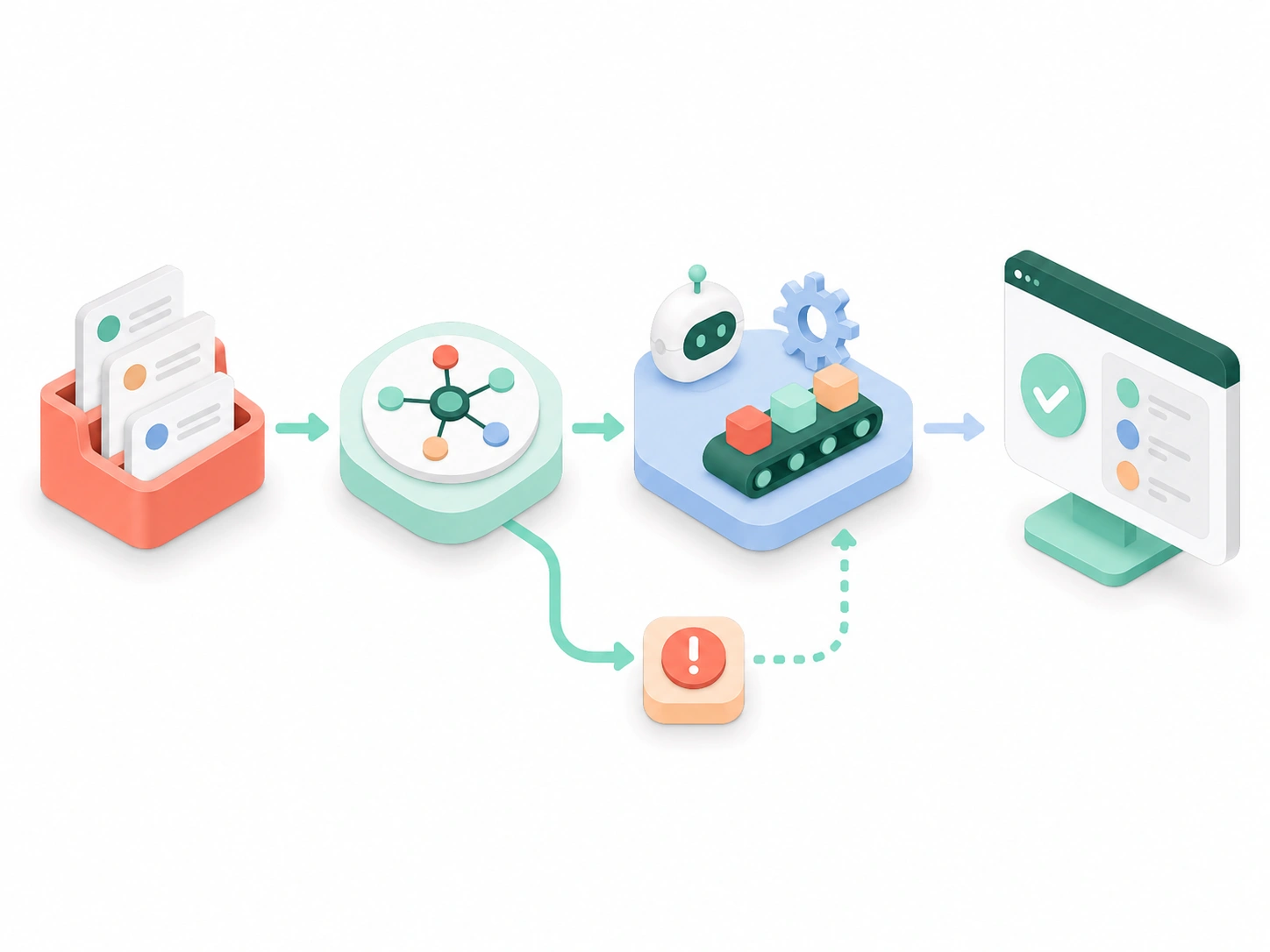
AI built for a business where every model faces a regulator, an auditor, and a customer's money. Fraud and AML detection, credit and underwriting support, customer-facing assistants, and document automation — engineered to be explainable, governed, and defensible, so they clear model-risk review and second-line challenge instead of stalling in it. Deployed in production, inside your perimeter.


A decade of AI engineering experience, validated in numbers

We map AI to the metrics that move in banking and insurance — loss rates, false-positive cost, cost-to-serve, and time-to-decision — and sequence use cases that can clear model-risk review, before any build.
Turn policies, regulations, product terms, and past cases into cited answers your teams and customers can trust — grounded retrieval, not a model guessing at what compliance requires.
Draft suspicious-activity reports, credit memos, and customer communications from your own data — with citations and a mandatory human sign-off, never an unchecked send.

Connect AI to the systems banks and insurers actually run — core banking, card and payment rails, policy administration, CRM, and your data warehouse — via secure connectors or MCP.

Agents that triage alerts, gather KYC evidence, and assemble case files — each with a defined authority scope and a human-approval gate on anything that moves money or a decision.
A governed customer and adviser assistant grounded in your products and policies — permission-aware, auditable, and safe to put in front of a regulated customer.

Orchestrate end-to-end processes — onboarding and KYC, claims, dispute handling — across specialized agents with approval gates: straight-through where it's safe, escalation where it isn't.

Production LLM applications — document intelligence, summarization, and copilots for analysts and advisers — engineered with evaluation, guardrails, and cost control for regulated use.

Detection and monitoring that catch fraud and money-laundering patterns while cutting the false positives that drown investigators — tuned to your risk appetite, with explainable alerts.

Decision support for credit, underwriting, and pricing — built for explainability and fair-lending scrutiny, so every decision can be evidenced to a regulator and to a declined applicant.
The controls that get AI past your model-risk function — documentation, validation, bias testing, audit trails, and monitoring aligned to SR 11-7, GDPR, and your regulators' expectations.
Our AI is tailored to the specific workflows, data environments, and governance requirements of each industry we serve.
Consulting & Advisory. Proposal and bid automation, engagement knowledge retrieval, and resource scheduling for multi-practice consultancies competing on speed and expertise.
Trusted by Rodic Consultants
SaaS & Digital Platforms. Build intelligent product experiences with in-product AI copilots, automated onboarding, and analytics agents that lift activation and retention.
Engineering & Infrastructure. Mine past project documentation for reuse, automate bid and tender responses, and speed up compliance and specification checks across engagements.
Financial Services. Automate document review, compliance checks, KYC workflows, and client reporting with governed, fully auditable AI.
Supply Chain & Logistics. Improve vendor communication, demand forecasting, and inventory intelligence with AI agents that act on live operational data.
Healthcare & Research. Enable medical document intelligence, research summarization, and secure knowledge assistants — built for privacy-sensitive, regulated environments.
CleanTech & Mobility. Support sustainability operations, energy monitoring, fleet intelligence, and ESG reporting with AI agents.
EdTech Platforms. Improve learner support, content operations, and course personalization with AI agents embedded inside your platform.
Non-Profits & Foundations. Automate grant research, donor communication, and impact reporting so teams spend more time on mission and less on paperwork.








We pair deep AI engineering with an understanding of how financial institutions are actually run — model risk, regulatory scrutiny, and customers' money — to ship AI that clears review and earns its keep.
Enterprise software delivery since 2009 — a track record built across technology cycles, not just the current AI wave.
Independently certified, annually audited — meets the security baseline enterprise procurement actually checks.

Nine in ten enterprise clients return for follow-on work — the only measure of delivery quality that cannot be faked.

Verified client reviews, independently collected — real feedback from real enterprise engagements.

Certified cloud partnerships with AWS and Microsoft Azure — enterprise infrastructure standards from day one.

DataSense, DocSense, BidSense — proprietary pre-built AI products that go live in weeks, not months of custom build.

IP, data, and strategy protected before the first discovery call ends — not after contracts are signed.

Post-deployment optimisation included in every engagement — we stay accountable until the system is performing.

Not the hype version — the honest one. Where AI earns its place in a business built on trust and regulation, the line the regulator draws, and what actually decides whether a model reaches production or dies in validation.
In a bank or insurer, a model that works in a notebook is the easy part. Getting it through independent validation, second-line challenge, and your model-risk framework is the real project — and it's where most financial-services AI quietly stalls.

A model built without your validation standards in mind fails second-line challenge and never recovers. We engineer for it from the first design decision — clear model purpose, documented data lineage, reproducible training, and defined performance and stability metrics — so validation becomes a checkpoint you pass rather than a wall you hit after months of work.
Your model-risk-management team needs more than a model that works — they need development documentation, assumptions and limitations, testing evidence, and an ongoing monitoring plan, aligned to frameworks like SR 11-7. We produce that as part of the build, not as a scramble the week before review, so the paper trail exists before anyone asks for it.
The AI that can't be governed never ships in finance, however impressive it is. We make access, monitoring, versioning, and audit first-class parts of the architecture — so 'who can use it, what did it do, and how is it controlled?' all have documented answers. That's what turns model risk from a blocker into a sign-off, and what lets the same discipline carry to the next use case.
If a model influences credit, pricing, or a claim, you have to be able to say why — to a regulator, an auditor, and the customer who was declined. Explainability isn't a nice-to-have in finance; it's a legal precondition for putting the model anywhere near a decision.

When a customer is declined or repriced, you're often legally required to tell them why in specific, accurate terms. A model that can't produce a defensible reason code is unusable for that decision, no matter how accurate it is. We build so every consequential output comes with the factors that drove it, in language a customer and a regulator can both accept.
Bolting an explanation onto an opaque model after the fact produces a story, not the truth. We choose techniques and architectures for the level of explainability the use case legally needs — sometimes a simpler, inherently interpretable model beats a marginally more accurate black box, and in regulated decisioning that trade is usually the right one.
Supervisors increasingly expect firms to explain automated decisions on demand — how the model works, what data it used, why this customer got this outcome. We produce that evidence as a designed-in capability, so 'show us how it decided' is a report you run, not a forensic investigation you dread.
Explainability isn't only a compliance obligation — it's how customers and front-line staff come to trust an automated decision. A clear, honest reason for an outcome defuses complaints and appeals, and turns a decision that would have felt arbitrary into one people can understand and, where warranted, challenge.
A fraud or AML model that flags everything is as useless as one that flags nothing — it just moves the cost onto an investigations team drowning in alerts. In financial crime, precision is the whole economics, not just recall.

Legacy rules engines generate huge volumes of false alerts, and every one costs an analyst's time to clear. The genuine fraud or laundering case then hides in the noise. Improving detection isn't only about catching more — it's about catching more while raising far fewer false alarms, which is where a well-built model earns its keep.
The right precision/recall balance is a business decision — a missed high-value fraud and a false block on a good customer have very different costs, and only you can set that trade-off. We tune the threshold to your risk appetite and the cost of each error, and make it adjustable as your exposure changes, rather than shipping one fixed number.
An alert that just says 'suspicious' wastes the investigation. We surface the specific signals behind each flag — the pattern, the anomaly, the linked entities — so an analyst starts the case with a reason, not a blank screen. That both speeds investigation and supports the suspicious-activity report if one is filed.
The goal is a detection system that lifts genuine catch rates and shrinks the false-positive queue at the same time — so your financial-crime team spends its hours on real cases, not clearing noise. That's the outcome that justifies the project to both the CFO and the MLRO, and it's measurable from day one.
AI can accelerate almost everything in a financial institution — but the line it must not cross is autonomously moving money or making a binding decision with no human able to answer for it. Defining that authority scope is the whole design.

Every agent we build has an explicit scope — what it may do on its own, what it must route to a human, and what it must refuse outright. That boundary is enforced in the system, not left to the model's discretion, so a clever prompt can't talk it into an action it was never authorised to take.
Payments, limit changes, account actions, and binding customer decisions route through a human-approval checkpoint sized to the consequence. Low-risk, high-volume steps run automatically; anything that could harm a customer or the firm waits for a person who can see the reasoning and own the call.
Human-in-the-loop doesn't mean humans on everything — that would waste the automation. The skill is drawing the line precisely: automate the clear, reversible, low-impact cases for speed, and reserve human judgment for the ambiguous and the irreversible. Done right, you get most of the efficiency without betting the firm on an unsupervised model.
Every decision, escalation, and override is logged and attributable, so you can reconstruct exactly what the AI did and why after the fact. In a regulated, money-moving environment that record isn't optional — it's what lets you answer an auditor, investigate an incident, and prove the human oversight was real.
A model that quietly disadvantages a protected group isn't only unfair — it's a fair-lending and conduct-risk exposure with regulators and courts attached. In financial services, fairness has to be tested and evidenced, not assumed.

Before a decisioning model goes anywhere near a customer, we test it for disparate impact across protected groups and document the results. A model that performs well on average can still produce a discriminatory pattern for a subgroup — and finding that in testing is far cheaper than finding it in a regulatory exam or a class action.
Fairness isn't a one-time certificate. As your customer mix and the economy shift, a model that was fair at launch can drift into bias. We monitor fairness metrics in production alongside accuracy, so a developing disparity is caught and corrected before it becomes a pattern of harm — and a finding against you.
You can exclude a protected attribute and still discriminate through a correlated proxy — a postcode, a device, a spending pattern. We probe for those proxies deliberately, because 'we didn't use race or gender' is not a defence if the model learned an effective stand-in for them. Catching proxy bias is where real fairness work happens.
Your second line and regulators want to see that fairness was assessed, how, and what you did about it. We produce that evidence — testing methodology, results, thresholds, and remediation — as part of the model file, so your compliance and conduct teams can defend the model rather than take its fairness on faith.
Financial data is among the most tightly governed there is. Where a model runs, what it can see, and who it shares with are questions your regulator, your DPO, and your customers all care about — and a third-party AI answer of 'trust us' won't survive.

For sensitive workloads we deploy inside your cloud tenant or fully self-hosted, on open-weight models where customer data never leaves your environment and no third-party API sees it. That's often the only architecture that clears a bank's data-protection and outsourcing review — and we design for it from the start rather than discovering the constraint at sign-off.
Residency rules, data minimisation, retention limits, and consent are engineered into the pipeline, not patched on — so the system aligns with GDPR and your local data-protection obligations. Sensitive fields are masked or tokenised where the task doesn't need them, and access is scoped and logged throughout.
Regulators treat AI as both a third-party and a model-risk concern, so we produce what your vendor-risk and outsourcing frameworks require — data-flow documentation, dependency mapping, and clear answers on where processing happens. The goal is an AI your risk function can attest to, not one that becomes a finding at the next exam.
The model, training data, and serving stack are yours, running on your infrastructure with no lock-in — and we never reuse your data to benefit anyone else. That ownership is what lets you evidence control of the whole system to a supervisor, and what turns a one-off build into a capability you keep and extend.
Weeks 1–2
We pinpoint the workflow with the best ROI for your institution — and the validation and governance realities around it — before any development begins.
Weeks 3–5
We build the core agent architecture, including model selection, tool connectors, memory, and orchestration logic.
Weeks 5–8
We connect the system to your PSA, CRM, document management, time & billing, and knowledge sources through secure data flows.
Weeks 8–9
We implement authority scopes, human-approval gates, audit trails, explainability, and monitoring — and produce the validation documentation so the system holds up to model-risk and regulatory review.
Weeks 9–12
We launch a controlled pilot, gather real-user feedback, refine the system, and move it into production with support.
Book a free 30-minute discovery call with a senior AI engineer — no slide deck, just questions about your workflows, your data, and your goals.
Enabled users to retrieve operational, financial, and project insights through natural language queries, transforming complex data analysis into instant, self-service intelligence.
See case studyWe pair best-in-class AI models, orchestration frameworks, and vector databases with the core systems banks and insurers actually run on — selecting the right combination for your stack, your use case, and your regulatory and data-residency requirements.
State-of-the-art models for reasoning, generation, and tool use.
Coordinate agents, tools, and workflows with reliability and control.
High-performance vector databases for semantic search and retrieval.
Store, recall, and manage agent memory and long-term state.
Modern languages and runtimes for building AI applications.
Connect to tools, APIs, and external systems seamlessly.
Monitor, trace, and evaluate AI systems in production.
Enterprise-grade cloud services and infrastructure foundations.
Financial institutions carry their customers' money and their most sensitive data — so AI must clear the model-risk, security, and data-protection bar your regulators and auditors hold you to. We design to the standards and frameworks financial services depend on, across AWS, Azure, and Google Cloud.

General Data Protection Regulation

Information Security Management Systems

System and Organization Controls
For AI applications in healthcare

Responsible AI principles and implementation

AI Risk Management

Principles and implementations
India’s personal data protection framework

Auditability frameworks

Standards and evaluation practices
Validate an AI agent use case with a low-risk, fixed-scope engagement designed to prove value, feasibility, and ROI before committing to a full build.
 Dedicated AI Team
Dedicated AI TeamA cross-functional AI agent team embedded into your environment — working within your processes, security requirements, and communication tools.
End-to-end delivery of a defined AI agent capability with fixed scope, timeline, and commercial terms. Full knowledge transfer and documentation included.
Let's discuss the right engagement model for your project?
Book a callFirst-hand experiences from financial institutions that put AI to work — governed, explainable, and measurable — and cleared review to reach production.
View all client testimonials“Vocso team has really creative folks and is very co-operative to implement client project expectations. MicroSave Consulting had great experience working with Anju and Prem.”

“Working with Deepak and his team at Vocso is always a pleasure. They employ talented staff and deliver professional quality work every time.”

“We love how our website turned out! Thank you so much VOCSO Digital Agency for all your hard work and dedication.”

“VOCSO SEO & SEM services helped me find new customers in a small budget. Their advanced SEO strategies made us visible to everyone.”

“Vocso team has really creative folks and is very co-operative to implement client project expectations. MicroSave Consulting had great experience working with Anju and Prem.”
“Working with Deepak and his team at Vocso is always a pleasure. They employ talented staff and deliver professional quality work every time.”
“We love how our website turned out! Thank you so much VOCSO Digital Agency for all your hard work and dedication.”
“VOCSO SEO & SEM services helped me find new customers in a small budget. Their advanced SEO strategies made us visible to everyone.”
The first AI project decides whether you get a second one. Pick something that touches a lending decision or moves money on day one, and you'll spend a year in model-risk review before anything ships — and a stalled pilot sours the whole programme.
In a financial institution, the best first use case is high-value, lower-liability, and measurable — so you prove the model and the governance approach together, on ground where a wrong answer doesn't reach a customer's account or a credit decision.
High volume, lower liability — Document processing, knowledge retrieval over policy, or an internal drafting copilot delivers real savings without the AI making a binding customer decision — so accuracy concerns don't block the win.
Human stays in the loop — Choose work where AI drafts or flags and a person decides — suspicious-activity triage, KYC evidence-gathering — so oversight is built in and validation is simpler.
Reachable, governed data — Pick a workflow whose data you can already access under existing permissions; if the inputs need a new data-sharing or privacy approval, factor that in or choose another start.
Measurable in one number — Success should be a single metric your CFO or COO already watches — false-positive rate, handling time, cost per case — so the result is undeniable.
At VOCSO, use-case selection is the first thing we do — because the highest-ROI workflow is rarely the flashiest, and in finance the wrong first choice buries the programme in review before it can prove anything.
In a bank or insurer, a model that works is only the beginning. It has to survive independent validation and second-line challenge under your model-risk framework — and a model built without that in mind fails the review and never recovers.
Model risk is where financial-services AI stalls, so we treat it as a design input, not a final gate. Build for validation from the first decision and the review becomes a checkpoint you pass rather than a wall you hit months in.
Document as you build — Model purpose, data lineage, assumptions, limitations, and testing evidence are produced during development, aligned to frameworks like SR 11-7 — not scrambled together the week before review.
Reproducible and versioned — Training is reproducible and every model version, dataset, and change is tracked, so validators can re-run and challenge what you did rather than take it on trust.
Defined performance & stability metrics — Agree the accuracy, stability, and monitoring thresholds up front, so 'is it good enough?' is answered against numbers your MRM function accepts.
An ongoing monitoring plan — Validation isn't one-off; we deliver the drift and performance monitoring that keeps the model inside its approved envelope after go-live.
VOCSO engineers for validation from day one — because in financial services, the most capable model in the world is worthless if it can't clear second-line challenge and reach production.
If a model influences whether someone gets credit, a policy, or a price, you must be able to say why — to a regulator, an auditor, and the customer who was declined. In finance, a decision you can't explain is a decision you can't legally make.
Explainability and fairness aren't features you bolt on at the end; they shape which model you can even use. Get them right and automated decisioning becomes defensible; get them wrong and it becomes a conduct-risk and fair-lending exposure.
Reason codes you can give — Every consequential decision comes with the specific factors that drove it, so you can issue an accurate adverse-action explanation instead of an opaque 'computer says no'.
Interpretable where it counts — For regulated decisioning we favour models you can genuinely explain, even over a marginally more accurate black box — because in this context the trade almost always favours transparency.
Test for disparate impact — We check performance across protected groups before launch and hunt for proxy variables, because excluding a protected attribute doesn't help if the model learned a stand-in for it.
Evidence on file — Fairness methodology, results, and remediation are documented for your conduct and compliance teams, so the model can be defended rather than taken on faith.
VOCSO builds explainability and fairness in from the design stage — because in financial services the question isn't only 'is the model accurate?', it's 'can you prove it's fair and justify every decision it makes?'
Legacy rules engines don't fail by missing fraud — they fail by flagging everything, drowning investigators in false alerts while the real case hides in the noise. The prize isn't just catching more; it's catching more while raising far fewer false alarms.
In financial crime, precision is the whole economics. A detection model that lifts genuine catch rates and shrinks the false-positive queue at the same time is what justifies the project to both the CFO and the MLRO.
Cut the false-positive load — Machine-learning detection reduces the volume of low-value alerts so analysts spend their hours on genuine risk, not clearing noise a rules engine created.
Tuned to your risk appetite — The precision/recall trade-off is a business decision — a missed high-value fraud and a false block on a good customer cost very differently — so we make the threshold yours to set and adjust.
Explainable alerts — Each flag carries the signals behind it — the pattern, the anomaly, the linked entities — so an investigator starts with a reason and the case supports a SAR if one is filed.
Adapts as threats evolve — Fraud typologies shift constantly; we build in monitoring and retraining so detection keeps pace instead of decaying into yesterday's patterns.
VOCSO builds detection that measures success in both directions — more real cases caught, fewer false alarms raised — because in AML and fraud, an accurate-sounding model that buries your team in alerts has negative ROI.
Financial data is among the most tightly governed there is. Where a model runs, what it can see, and who it shares with are questions your regulator, your DPO, and your customers all care about — and a third-party AI answer of 'trust us' won't survive a review.
For most sensitive financial workloads, the deployment architecture decides whether the project clears data-protection and outsourcing review at all. We design for that constraint from the start rather than discovering it at sign-off.
Run in your environment — For sensitive data we deploy inside your cloud tenant or fully self-hosted, on open-weight models, so customer data never leaves your perimeter or reaches a third-party API.
Privacy and residency by design — Data minimisation, residency rules, retention limits, masking, and consent are engineered into the pipeline to align with GDPR and your local obligations — not patched on later.
Third-party & outsourcing risk covered — We produce the data-flow documentation, dependency mapping, and processing-location answers your vendor-risk and outsourcing frameworks require.
You own the whole stack — The model, data, and serving pipeline are yours with no lock-in, and your data is never reused — so you can attest control of the system end to end.
VOCSO designs the data architecture around your obligations first — because in financial services, an AI that can't answer 'where does our data go?' with evidence will never clear the review, no matter how capable it is.
"It feels faster" won't survive a risk-and-finance committee. To fund the next phase of AI, you have to prove its value in the metrics that already run the institution — loss, cost, and risk, not vanity numbers.
Financial institutions already live by a handful of figures — loss rates, cost-to-serve, straight-through-processing, false-positive cost. The strongest AI business case doesn't invent new metrics; it moves the ones leadership and the regulator already watch.
Loss & false-positive cost — Track fraud/AML detection against dollars of loss avoided and the investigation hours saved by fewer false alerts — the clearest line from AI to the P&L.
Cost-to-serve & handling time — Measure how document automation and assistants cut cost per case and handling time in operations, onboarding, and servicing.
Straight-through & decision speed — Quantify the share of cases handled straight-through where safe, and the time-to-decision on the rest — capacity and customer experience in one number.
Baseline before you build — We capture the 'before' numbers up front, so the improvement is provable and credited to the AI rather than argued about later.
VOCSO instruments the business case in your institution's own language — so when the committee asks what AI is worth, the answer is a number on the metrics they already trust, and the budget to scale follows.
You delivered exactly what you said you would in exactly the budget and in exactly the timeline.





Most institutions start with one high-value workflow — document automation, fraud/AML triage, or a knowledge assistant over policy and regulation. We help you scope it, prove the value, and define the validation and security path before you scale. No open-ended contracts. No ambiguous scope.
deepak@vocso.com — no forms, no funnels.
That's exactly what we build for — it's where financial-services AI usually stalls. We engineer to your model-risk framework from day one: documented model purpose, data lineage, reproducible training, defined performance and stability metrics, and an ongoing monitoring plan, aligned to standards like SR 11-7. We produce the development documentation, testing evidence, and stated limitations your independent validators and second line need to challenge and sign off the model — so validation confirms controls already in place rather than sending the project back to the drawing board.
It depends on scope, integration depth, and governance. A focused, lower-liability build (e.g. document automation or an internal knowledge assistant) typically runs $30,000–$80,000; a decisioning, fraud/AML, or core-integrated system with full model-risk documentation and monitoring runs $80,000–$250,000+. We almost always start with a fixed-price PoC (typically $15,000–$25,000) that proves value on your real data and defines the validation path before you commit. Every engagement opens with a free discovery call for a realistic estimate — and an honest view of the likely ROI and the review effort involved.
A focused PoC delivers a working system on your real data in 4–6 weeks. A production capability for a single high-value use case typically takes 12–20 weeks — longer than an unregulated build because model validation, explainability evidence, and security review are part of the path, not an afterthought. The biggest variables are data-access approvals and the depth of model-risk review your use case triggers. We sequence delivery so you see working software early and the validation never becomes a surprise at the end.
For any model touching credit, pricing, or a claim, explainability is a legal precondition, so we design for it rather than bolt it on. Every consequential decision comes with the specific factors that drove it, so you can issue an accurate adverse-action reason instead of an opaque 'computer says no'. Where regulation demands it, we favour inherently interpretable models even over a marginally more accurate black box, and we produce the evidence your regulator and conduct team need to see exactly how a given customer got a given outcome — on demand, as a report you run, not a forensic exercise.
Yes — doing exactly that is the point of doing it well. Rules engines fail by flagging everything and burying investigators in false alerts while the real case hides in the noise. We build machine-learning detection that lifts genuine catch rates while cutting the false-positive queue, tuned to your risk appetite and the very different costs of a missed high-value fraud versus a false block on a good customer. Every alert carries the signals behind it so an investigator starts with a reason and can support a SAR, and we monitor and retrain as fraud typologies shift.
No — and any vendor comfortable with AI autonomously moving money or making binding decisions should worry you. Every agent has an explicit authority scope: what it may do alone, what it must escalate, and what it must refuse — enforced in the system, not left to the model's discretion. Payments, limit changes, and binding customer decisions route through a human-approval gate sized to the consequence, while low-risk, reversible steps run straight-through. Every action is logged and attributable, so the human oversight is real, and provable to an auditor.
We treat bias as a legal risk, not just a technical one. Before a decisioning model launches, we test it for disparate impact across protected groups and deliberately hunt for proxy variables — because excluding a protected attribute doesn't help if the model learned a correlated stand-in like a postcode or device. Fairness metrics are then monitored in production alongside accuracy, so a developing disparity is caught before it becomes a pattern of harm. The methodology, results, thresholds, and any remediation go into the model file for your conduct and compliance teams to defend.
Yes to both. For sensitive workloads we deploy inside your cloud tenant or fully self-hosted on open-weight models, so customer data never leaves your perimeter and no third-party API sees it — often the only architecture that clears a bank's data-protection and outsourcing review. Privacy, residency, retention, and masking are engineered in to align with GDPR and your local rules. And ownership is unconditional: the model, training data, code, and serving stack are yours; we sign NDAs before discovery, retain nothing after a project concludes, and never reuse your data to benefit anyone else.
We're a build partner, not a certification body, but we design to the controls behind the frameworks financial services rely on — SR 11-7 model risk, GDPR and local data protection, SOC 2, ISO 27001, PCI-DSS where cards are involved, DORA for operational resilience, and emerging AI-specific regulation such as the EU AI Act. We map your specific obligations to concrete system controls during discovery and produce the documentation your compliance, audit, and risk functions need — so compliance is engineered in rather than bolted on before launch.
Yes — integration is the hard part of financial-services AI and a core strength for us. We connect to core banking, card and payment rails, policy administration, CRM, and your data warehouse through whatever they expose — modern APIs, message queues, secure file transfer — and build structured wrappers for legacy systems without clean APIs so you avoid a risky migration. The AI inherits your existing entitlements and permission model rather than bypassing it, and any write-back into a system of record gets validation, idempotency, and rollback paths.
The best first use case is high-value, lower-liability, and measurable — so you prove the model and the governance approach together without a wrong answer reaching a customer's account or a credit decision. For most institutions that's document processing, an internal knowledge assistant over policy and regulation, or human-in-the-loop financial-crime triage. Starting there sidesteps the heaviest validation while proving value, and earns the internal trust to take AI toward decisioning later. We help you pick deliberately, because in finance the wrong first choice buries the programme in review before it proves anything.
Yes — and in finance the ongoing part is non-negotiable. Every engagement includes a period of post-launch support (monitoring, incident response, performance review), and retainers cover the model governance regulators expect: drift and fairness monitoring, periodic re-validation against fresh data, retraining as fraud patterns or the economy shift, and documentation updates. Because models degrade quietly rather than failing loudly, this monitoring is what keeps them inside their approved envelope — which is why we define operational and model ownership before go-live, not after.
The capabilities that make up a financial institution's AI program — from the consulting and strategy that scopes it, to the RAG, agents, and integration that deliver it, to the governance and model risk that let you run it on regulated, money-moving work.