

Table of Contents
RAG Development
Retrieval-Augmented Generation for grounded enterprise AI
- ✔️ Combines internal knowledge base with LLM
- ✔️ Reduces hallucinations, boosts trust
- ✔️ Powered by vector search + embeddings
- ✔️ Perfect for enterprise documentation, SOPs
![]()
Colleges18
India’s College Search Platform
Programmatic SEO powered platform listing 12,000+ colleges across India. Built with Next.js, Strapi, Postgres, and AWS S3 for blazing performance.
- ✔️ 500+ leads in 1st month
- ✔️ Loads under 3 seconds
- ✔️ 200+ categories, 50+ pages
![]()
Data is everywhere — but accessible insights are not. Businesses sit on top of terabytes of data housed in structured relational databases like PostgreSQL, MySQL, and SQL Server. However, despite the widespread adoption of business intelligence tools, many non-technical stakeholders still struggle to extract the information they need. The bottleneck? SQL. Structured Query Language (SQL) is a powerful yet complex tool for interacting with relational databases. While it remains the standard for querying structured data, its syntax, logic, and database-specific nuances make it difficult for business users, marketers, product managers, and executives to utilize effectively. These users often rely on data analysts to prepare the reports or engineers to write queries on their behalf — resulting in delays, misunderstandings, and inefficiencies.
This challenge presents a significant opportunity: what if business users could simply ask a question in plain English — like “What were the total sales in Q1 across all regions?” — and instantly receive an accurate, secure SQL-generated answer? We will explore how to build an AI-powered chatbot that translates natural language into SQL, leveraging large language models (LLMs), semantic embeddings, business rule processing, and natural language understanding (NLU). The goal is to bridge the gap between raw data and decision-making, enabling real-time insights without writing a single line of SQL. We’ll walk through the architectural design, data preparation, language understanding components, and system integration needed to implement such a system — whether for internal dashboards, enterprise analytics tools, or external customer portals.
Table of Contents
1. System Overview & Architecture
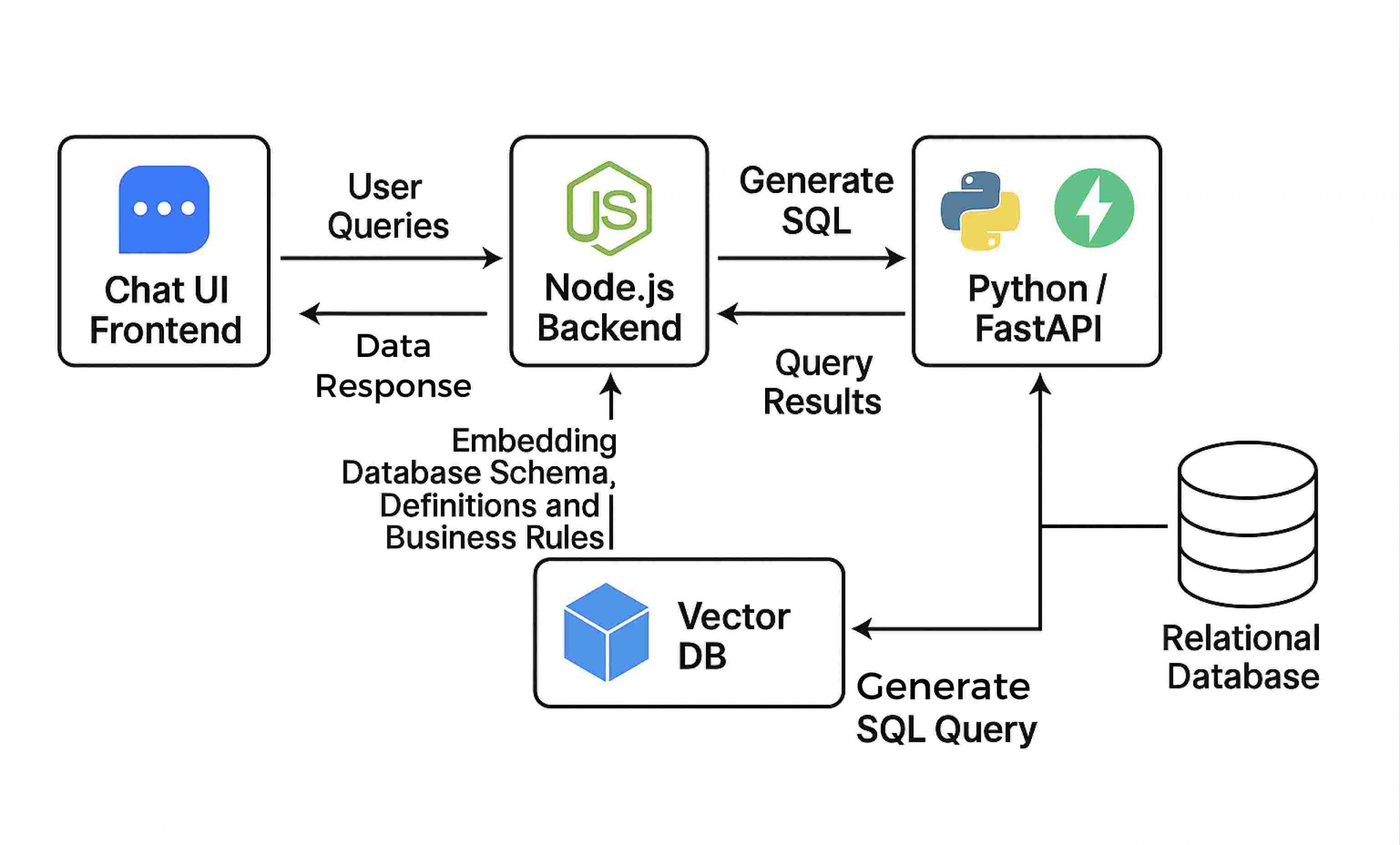
At the core of this AI chatbot lies a modular architecture that integrates natural language interfaces with traditional database systems. To build a system capable of reliably converting natural language into SQL queries, we need to consider several interconnected components. Want to build a fast, scalable backend for your AI chatbot? Explore our Backend Development Services to get started with robust APIs and database architecture.
Frontend Interface (Chat UI)
The user interface acts as the entry point. It could be a simple chatbox embedded into a web dashboard or a more elaborate conversational assistant within an enterprise app. Users type natural language queries like, “Compare monthly revenue in India vs the US,” and expect relevant responses.
Key UI considerations include:
- Multi-turn memory for follow-up queries.
- Support for explanations and clarifications.
- Visualization support (tables, graphs, summaries).
Backend Query Processor
The backend is the engine room where interpretation, processing, and execution happen. The primary job here is to translate the user’s question into an accurate SQL query that respects schema structure, business rules, and user permissions.
This involves:
- Calling the LLM with a properly engineered prompt.
- Injecting schema context and business rules.
- Running the final query against the target database.
- Formatting results for the frontend.
LLM Integration (Natural Language to SQL)
The most critical component is the large language model—such as OpenAI’s GPT-4 or open-source alternatives like LLaMA or Mixtral—which handles translation from natural language to SQL. However, LLMs don’t natively “know” your database schema. They must be primed with context using retrieval-augmented generation (RAG), schema embeddings, and structured prompts.
Vector Databases
Vector databases like FAISS, Chroma, or Pinecone store semantic embeddings for both the schema and business rules. When the user submits a query, the system performs a semantic search to fetch relevant tables, columns, and constraints, then injects this information into the LLM prompt to guide accurate SQL generation.
NLU Engine
To enhance understanding and precision, an NLU engine is used to extract intent (e.g., retrieve, filter, compare) and key entities (e.g., products, locations, dates) from the user’s input. This can be handled using spaCy, Rasa, or LLM-based parsing techniques.
The architecture combines these building blocks into a pipeline that moves from query understanding to response generation. By aligning traditional relational data practices with modern NLP advances, we enable a true self-service analytics experience.
2. Schema Embeddings for LLM Grounding
One of the biggest reasons LLMs hallucinate or generate invalid SQL is because they lack awareness of your actual database schema. To mitigate this, we must train the LLM to “understand” the structure of your database before it ever attempts to answer a user query. If your application relies on structured content, combining AI with a modern CMS can be powerful. Strapi Headless CMS Development helps you manage and deliver structured schema to your AI models more effectively.
Extracting the Schema
Begin by extracting the full schema of your database. This includes:
- Table names
- Column names and data types
- Primary and foreign key relationships
- Constraints and indexes
The schema is more than just structure—it carries business meaning. Add metadata and short descriptions to make each component more interpretable. For example:
{
"table": "orders",
"description": "Stores all purchase orders placed by customers.",
"columns": [
{
"name": "amount",
"type": "decimal",
"description": "Total monetary value of the order."
},
{
"name": "region_id",
"type": "integer",
"description": "Foreign key linking to the customer region."
}
]
}Creating and Storing Embeddings
Once you have a structured schema, transform it into embeddings using models like:
- OpenAI Embeddings API
- SentenceTransformers
- InstructorXL
These embeddings are then stored in a vector database. When a user query arrives, it is also embedded and compared via cosine similarity to schema embeddings. This allows the system to identify the most relevant tables and columns—regardless of whether the user used the exact terminology.
Semantic Schema Retrieval
Consider a user question like: “Show me revenue by region.”
Even though the database has no column explicitly named “revenue,” the semantic search will associate “revenue” with the “amount” field in the orders table, and “region” with the regions.name field.
The chatbot retrieves:
- orders.amount
- regions.name
- joins between orders and regions
This context is then added to the LLM prompt to generate SQL grounded in actual schema.
3. Business Rules Embedding (Domain-Specific Context)
Schema knowledge alone isn’t enough. Every organization has operational rules and domain-specific logic that should influence query generation. For instance, your finance department might calculate quarters starting from April, or certain accounts may always be filtered out from analysis. Embedding business rules into AI workflows is a all rounder strategy. Learn how our AI Development Services can help you integrate custom logic into LLM prompts.
Common Business Rule Examples
Some typical business rules include:
- Exclude test or inactive users
- Only include completed transactions
- Fiscal year starts in April
- Product category filters
- Internal departments to be excluded
Converting Rules into Natural Language
These rules need to be converted into plain English explanations that can be understood and processed by an LLM. For example:
“Ignore any order where is_test = true.”
“Fiscal year starts in April, not January.”
“Only include users where is_active = true.”This textual representation helps align the AI’s understanding with real-world operations.
Embedding and Retrieval
Once translated into plain language, these rules are embedded using the same model as the schema. They’re stored in the vector database and retrieved in real-time based on query context.
When the user asks a question like:
“What were Q1 revenues?”The system recognizes that Q1 in this business context starts in April and modifies the query timeframe accordingly. Similarly, if a question involves user data, it ensures is_active = true is always included in the WHERE clause.
Accuracy and Compliance
Embedding business rules drastically improves both the accuracy and compliance of generated SQL. It ensures that queries reflect internal policies and regulatory constraints, minimizing the risk of misinterpretation or reporting errors.
4. Natural Language Understanding (NLU)
Before we feed anything into a large language model, it helps to first break down the user’s intent and extract key entities from their query. This preprocessing step—called Natural Language Understanding (NLU)—can significantly improve the quality, relevance, and precision of the resulting SQL.
Why NLU Matters in SQL Generation
Language is ambiguous. The phrase “sales of iPhones in Mumbai last quarter” involves multiple layers of meaning:
- “Sales” implies aggregating data (e.g., summing revenue or counting transactions).
- “iPhones” suggests a specific product filter.
- “Mumbai” is a geographical constraint.
- “Last quarter” is a relative time frame that needs conversion.
NLU helps extract these meanings in a structured way before handing off to the LLM.
Intent Detection
Intent is the user’s goal in the query. Common intents in SQL-focused chatbots include:
- Retrieve data (e.g., “Get sales of Q1”)
- Compare entities (e.g., “Compare revenue between product A and B”)
- Apply filters (e.g., “Show only active users”)
- Summarize (e.g., “What’s the average revenue per customer?”)
Intent detection can be achieved using:
- Rule-based approaches with keyword matching
- ML models like BERT or spaCy pipelines
- LLM function calling or classification prompts
Knowing the intent helps guide the structure of the resulting SQL query (SELECT, GROUP BY, WHERE, etc.).
Entity Extraction
Entities are the “nouns” in the query: products, dates, categories, locations, user segments, etc.
Example input:
“Show iPhone sales in Mumbai last quarter”Extracted entities:
- Product: iPhone
- Location: Mumbai
- Time: last quarter
These can be resolved against known values in the database using entity linking techniques or lookup tables. Some systems pre-index key column values to match user input against real data (e.g., mapping “iPhones” to products.name = ‘iPhone 13’).
Improving Accuracy with NLU
Using NLU to extract intent and entities early in the pipeline helps:
- Select appropriate schema elements from the vector DB.
- Include resolved entities in the LLM prompt.
- Reduce hallucinations by providing more structured context.
Combining NLU with semantic embeddings and business rules leads to significantly more precise SQL outputs.
5. Prompt Engineering for SQL Generation
With schema context, business rules, and structured entities in hand, we’re ready to generate SQL. But LLMs are only as good as the instructions they’re given. This is where prompt engineering becomes critical. If you Want to prevent hallucination and ensure grounded responses in AI output? RAG Development Services helps you to implement Retrieval-Augmented Generation for context-aware, accurate SQL prompts.
Why Prompt Engineering Matters
Even advanced LLMs like GPT-4 don’t natively understand your specific database. Without context, they’ll either guess or hallucinate. The job of prompt engineering is to prime the model with everything it needs to write a safe, accurate query:
- Relevant schema details
- Applicable business rules
- Clarified intent
- Key entities
Example of a Well-Structured Prompt
Let’s say the user asked:
“Show sales by region for last quarter.”The system gathers the following:
- Tables: orders, regions
- Fields: orders.amount, orders.date, regions.name
- Business rules: is_test = false, fiscal year starts in April
- Entity: “last quarter” = Q1 (April–June if FY starts in April)
Now, the prompt sent to the LLM might look like:
You are an assistant that generates SQL queries for a PostgreSQL database.
Tables:
- orders (id, amount, date, region_id, is_test)
- regions (id, name)Business Rules:
- Ignore orders where is_test = true
- Fiscal year starts in AprilUser Question:
Show sales by region for last quarter.Generate the SQL query.
The output might be:
SELECT r.name AS region, SUM(o.amount) AS total_sales
FROM orders o
JOIN regions r ON o.region_id = r.id
WHERE o.is_test = false
AND o.date BETWEEN '2025-04-01' AND '2025-06-30'
GROUP BY r.name;Prompt Safety Tips
- Use templates: Always follow a consistent structure — context first, then the user query.
- Limit hallucination: Avoid ambiguous or open-ended instructions.
- Validate outputs: Run query plans, use linting tools, or manually review outputs in sandbox environments.
- Inject entity values: Instead of “iPhone,” resolve to an actual product ID or canonical name.
Prompt engineering is an art backed by empirical iteration. Test prompts thoroughly with different types of questions—time filters, joins, aggregations, and edge cases.
6. SQL Execution and Response
Once the LLM generates SQL, the next step is to execute it against the target relational database. However, this is not just a fire-and-forget operation — there are important safety, formatting, and UX considerations. In Web applications, Designing interactive UIs to display charts and summaries from SQL results is most challenging task. ReactJS Development is popular among tech companies for building intelligent, dynamic dashboards and chatbot frontends.
Execution Safety
Blindly running LLM-generated SQL can lead to security risks, long-running queries, or incorrect data exposure. Add safety layers such as:
- Whitelisting: Only allow queries on specific tables or columns.
- Static analysis: Check for dangerous keywords (e.g., DROP, DELETE, etc.).
- Query plans: Estimate performance cost before execution.
- Timeouts and limits: Prevent infinite scans on large tables.
Consider using a staging database or views with row-level security for added protection.
Executing the SQL
Once validated, run the query using standard connectors:
- psycopg2 for PostgreSQL
- mysql-connector-python for MySQL
- pyodbc for MSSQL
After running query, Capture:
- Result rows
- Column headers
- Data types
Errors should be gracefully handled with user-friendly messages (“No data found,” “Check your date filter,” etc.).
Formatting the Output
Not all users want a raw SQL dump. Presenting results in a digestible format boosts understanding and satisfaction.
Support multiple formats:
- Tabular data: Ideal for most dashboards.
- Natural language summary: “Total revenue for Q1 in Mumbai was $1.2M.”
- Charts: If the result contains grouping or time series, show bar/line charts.
Tooling for rendering:
- Recharts or Chart.js in frontend
- Matplotlib for server-side chart generation
- CSV or Excel for downloadable results
Let users customize output preferences (grouped tables, chart type, etc.).
7. Add-ons for Better UX
To truly deliver a helpful conversational data assistant, think beyond basic question-answering. The real magic lies in small usability enhancements that mimic a good human analyst.
Chat Memory (Follow-ups)
Enable multi-turn conversations by maintaining chat memory. This allows users to ask:
“Break that down by product.”
“What about just for iPhones?”By referencing prior queries and results, the system can:
- Retain selected filters
- Add new grouping dimensions
- Drill down or zoom out
Memory handling can be done using:
- Chat history token windows
- Named entity tracking
- Prompt chaining
Synonym & Fuzzy Matching
Users often don’t use the exact column or table names. Examples:
- “Revenue” vs “sales”
- “Clients” vs “customers”
- “Q1” vs “Jan–Mar”
Use embedding-based semantic matching or build a domain-specific synonym dictionary. This improves entity resolution accuracy and reduces confusion.
Explainability
Just showing results isn’t always enough. Offer simple explanations:
“This chart displays total sales grouped by region from April to June 2025, excluding test orders.”This builds trust and helps users verify correctness, especially in high-stakes environments like finance or healthcare.
Export and Sharing
Allow users to:
- Download results in CSV or Excel
- Generate PDF summaries
- Share query links within the organization
These small additions transform a chatbot from a novelty into a genuinely useful BI companion.
8. Tools & Stack Recommendations
Building an AI chatbot that can seamlessly query relational databases is not a trivial task — it involves combining multiple components, each of which requires the right tools. Here’s a breakdown of the recommended stack for each layer of the system. In scenarios where your chatbot needs to pull in external insights — like competitor pricing, user reviews, or region-specific rules — integrating automated Web Scraping Services can significantly boost context accuracy.
Embedding Models
These models generate dense vector representations of your schema metadata and business rules so that the LLM can semantically understand them.
- OpenAI Embeddings (text-embedding-3-small/large): High-quality, reliable, integrates seamlessly with GPT prompts.
- InstructorXL: Allows embedding generation with task-specific instructions; helpful for schema context.
- SentenceTransformers: Open-source, customizable, good for private/local deployments.
LLMs (Large Language Models)
These are at the core of natural language → SQL generation. Choose based on your use case, cost sensitivity, and latency expectations.
- GPT-4 (OpenAI): Best-in-class reasoning, strong SQL capabilities, reliable.
- Claude (Anthropic): Strong contextual retention, safe for enterprise use.
- Mixtral (Mistral): Cost-effective, open-weight option for advanced users.
- LLaMA via Groq: Ultra-fast inference when deployed on Groq hardware; great for real-time applications.
Natural Language Understanding (NLU)
For intent detection and entity extraction, you can combine traditional NLP with newer LLM techniques.
- spaCy: Lightweight, customizable pipelines for NER and POS tagging.
- Rasa: Built-in support for intent/entity training, great for hybrid ML-rule-based models.
- OpenAI Function Calling: Newer approach where LLM is guided to extract structured outputs based on predefined schemas.
Vector Databases
Vector databases store your embedded schema and business rule data, allowing fast semantic search at runtime.
- FAISS (Facebook AI): Open-source, performant for in-memory embedding retrieval.
- Pinecone: Fully managed, scalable, easy integration with Python/NodeJS apps.
- Chroma: Lightweight and open-source, excellent for rapid prototyping.
Backend APIs
This is where prompt construction, vector retrieval, SQL generation, and execution are orchestrated.
- FastAPI (Python): Highly performant, async support, built-in validation.
- NodeJS (Express/NestJS): Great if your stack is JavaScript-based, integrates well with frontend.
Databases
The target system your chatbot is querying.
- PostgreSQL: Excellent for analytics, strong SQL dialect.
- MySQL: Popular and fast for most CRUD workloads.
- MSSQL: Ideal for enterprise environments with heavy reporting tools.
Frontend UI
For the chat interface and result visualizations, go with a modern and responsive frontend stack.
- NextJS: Server-side rendering support, easy API routes, React-based.
- Tailwind CSS: Clean design system for rapid styling.
- Recharts / Chart.js / D3.js: Visualize data effectively with bar charts, pie charts, and time series.
By using this curated stack, you can go from prototype to production quickly while maintaining modularity, performance, and flexibility.
9. Challenges & Tips
No project of this complexity comes without challenges. Here are some of the most common ones you’ll encounter and tips to mitigate them. For robust backend logic, request handling, and real-time data flow in your chatbot application, NodeJS is the most trusted backend to consider for the reliability of the application.
Ambiguous User Queries
Problem: Many natural language questions are vague or contextually incomplete.
Example: “Show performance data.”
Solution:
- Prompt the user for clarification: “Which metric do you mean by performance?”
- Offer auto-suggestions or dropdown filters to guide their phrasing.
- Store previous user interactions to resolve context in multi-turn chats.
Hallucination from LLMs
Problem: LLMs might invent non-existent columns or make incorrect assumptions if the prompt isn’t grounded properly.
Solution:
- Use RAG (Retrieval-Augmented Generation) for Retrieval of schema and rules before prompting.
- Validate generated SQL by checking against actual schema metadata.
- Log failed attempts and retrain prompt strategies over time.
Latency in Real-Time Applications
Problem: Vector search + LLM generation + SQL execution can take 2–10 seconds per request.
Solution:
- Use Groq or other inference-optimized platforms for low-latency responses.
- Pre-compute and cache embeddings and schema context.
- Implement query caching for popular or repeated user questions.
Maintaining Security & Governance
Problem: Sensitive data may be accidentally exposed if queries aren’t filtered properly.
Solution:
- Whitelist fields and tables accessible to the chatbot.
- Enforce row-level security based on user roles.
- Add a review interface for admins to monitor and approve query types.
Managing Non-Standard Business Logic
Problem: Business rules vary between departments and evolve over time.
Solution:
- Modularize business rules in vector stores with metadata tags (e.g., “finance_only”).
- Version your rule embeddings and tie them to specific query templates.
- Let domain experts edit rule descriptions using a no-code admin panel.
By proactively handling these challenges, you can deliver a robust system that’s resilient, scalable, and trustworthy.
Conclusion
As modern organizations become increasingly data-centric, the demand for intuitive, self-service data tools has never been higher. Traditional SQL-based systems, while powerful, often alienate non-technical users who struggle with query syntax and database logic. AI chatbots designed to interpret natural language and generate accurate SQL queries offer a game-changing solution. By combining large language models with schema-aware embeddings, embedded business logic, and robust prompt engineering, these systems allow anyone — from marketing analysts to sales leaders — to access data-driven insights without writing a single line of code. This not only boosts operational efficiency but also creates a culture of data ownership across all levels of the organization.
The architecture presented in this guide enables a modular and scalable approach to solving this challenge. Whether you use open-source tools or integrate commercial LLM APIs, the key lies in grounding AI with the right context — both technical and domain-specific. By embedding your schema and business rules, detecting user intent accurately, and validating outputs before execution, you transform a chatbot into a reliable data assistant. From powering internal dashboards to driving client-facing analytics, this approach ensures that data becomes an accessible asset, not a gated resource. As AI tooling continues to evolve, so too will the potential to reimagine how businesses interact with their data — making conversations, not queries, the new interface to insight.














